Stateless vs. Cacheable: Understanding the Key Differences



In the intricate landscape of modern distributed systems, where services communicate over networks and users expect instantaneous, reliable interactions, the architectural choices made at fundamental levels profoundly impact performance, scalability, and resilience. Among the most pivotal of these choices are the principles of statelessness and cacheability. While often discussed in conjunction, or sometimes even conflated, these two concepts address distinct concerns and offer unique benefits to software design. Grasping their nuances is not merely an academic exercise; it is an imperative for anyone involved in crafting robust, high-performance applications, particularly in the realm of API development and API gateway management.
The rise of microservices, cloud computing, and diverse client platforms has intensified the need for well-defined API interactions. Whether you're designing a public API for developers, orchestrating internal services, or deploying a sophisticated API gateway to manage traffic, a clear understanding of when and how to apply stateless and cacheable patterns is paramount. These principles dictate how data is managed, how services interact, and ultimately, how efficiently resources are utilized. This comprehensive exploration will delve deep into the definitions, core characteristics, advantages, disadvantages, and practical implications of both stateless and cacheable architectures. By dissecting their individual strengths and understanding their powerful synergy, we aim to equip architects, developers, and system administrators with the insights needed to make informed design decisions that lead to more resilient, performant, and scalable API ecosystems.
Part 1: Deconstructing Statelessness – The Foundation of Modern Web Architectures
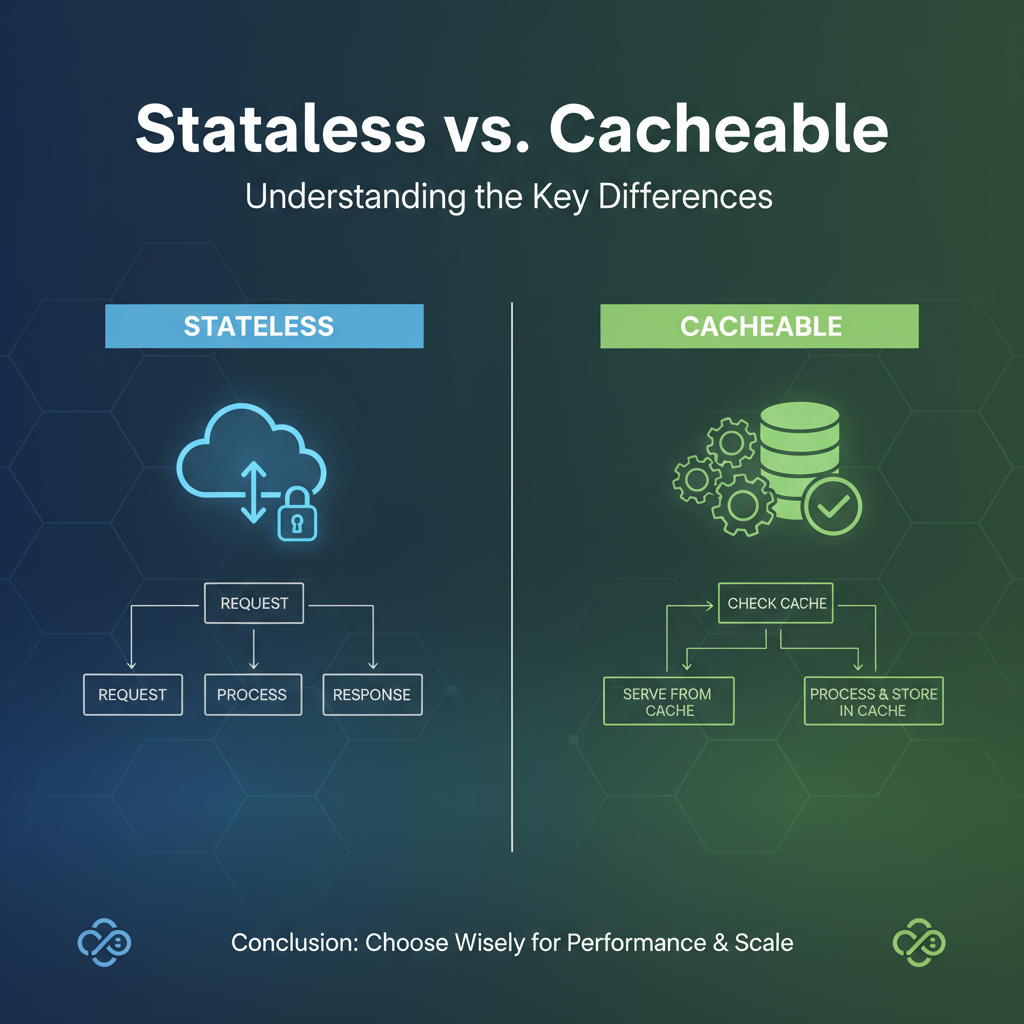
At its core, statelessness is an architectural principle asserting that a server should not store any information about the client's session state between requests. Each request from a client to a server must contain all the information necessary to understand and process the request independently. The server processes the request based solely on the data provided within that specific request and responds, then immediately forgets any context related to that interaction. There is no memory of past requests or anticipation of future ones.
Definition of Stateless: An Independent Exchange
To truly appreciate statelessness, we first need to define "state" in the context of client-server interactions. State refers to any data or context that a server needs to remember about a client's ongoing interaction. For instance, in a traditional stateful application, a server might remember that a particular user is logged in, has items in their shopping cart, or is currently on a specific step of a multi-step form. This information is typically stored in server-side sessions, tied to a unique session ID passed between the client and server.
Statelessness, conversely, dictates the complete absence of such server-side memory. When a client makes a request, the server treats it as if it's the first and only request from that client. Any information that would traditionally be part of a server-side session – like user authentication details, transaction identifiers, or application-specific context – must instead be explicitly included in each request by the client. This means that a server handling a request does not rely on any preceding requests from the same client to fulfill the current one. It can pick up any request at any time, process it, and return a response, without needing to retrieve or maintain any client-specific conversational state on its end. This fundamental detachment between individual requests transforms how entire systems are designed, from the simple API call to the complex orchestration within an API gateway.
Core Principles and Characteristics of Stateless Architectures
The principle of statelessness underpins several key characteristics that define the behavior and capabilities of systems built upon it:
- Self-Contained Requests: Every single request from the client to the server must be complete and understandable on its own. It includes all necessary data, parameters, authentication tokens, and any other context required for the server to process it without relying on previous interactions. For example, instead of a server remembering a user is logged in, each request might carry a JSON Web Token (JWT) that authenticates the user.
- No Session Affinity Required: In stateful systems, clients often need to stick to the same server for the duration of a session because that server holds their session state. This is known as session affinity or sticky sessions. In a stateless system, since no server holds client state, any request from a client can be handled by any available server. This significantly simplifies load balancing and horizontal scaling strategies, as requests can be distributed uniformly across a pool of servers without concern for continuity.
- Ease of Scaling (Horizontal Scaling): This is perhaps the most celebrated advantage. Because servers don't maintain individual client states, new servers can be added or removed from the system at will, horizontally scaling to meet demand. A request coming in can be routed to any instance of the service. If one server goes down, another can immediately take over without any loss of client context, as that context resides with the client or is part of the request itself. This architectural pattern is crucial for high-availability and elastic cloud environments.
- Fault Tolerance and Resilience: The failure of an individual server instance in a stateless system does not lead to a loss of client session data. While an in-flight request might fail and need to be retried by the client, the overall system remains robust. Clients can simply resubmit their request to another available server. This inherent resilience makes stateless architectures highly desirable for mission-critical applications where downtime must be minimized.
- Predictability and Debugging Simplicity: Each request is an isolated event. This isolation makes stateless systems generally easier to understand, test, and debug. When an issue occurs, it’s usually contained within the scope of a single request, rather than being tangled in a long-running, complex session state. Reproducing issues becomes simpler, as one doesn't need to replicate an entire sequence of past interactions.
These characteristics collectively make statelessness a cornerstone of modern distributed system design, particularly for APIs and the gateways that manage them.
Advantages of Stateless Architectures
The benefits derived from adopting a stateless approach are profound and far-reaching, influencing everything from system architecture to operational efficiency:
- Superior Scalability: The ability to scale horizontally with ease is arguably the most significant advantage. Without the burden of session state, load balancers can distribute incoming requests across any available server instance without concern for 'sticky sessions.' This allows for seamless elasticity, enabling systems to dynamically adjust to varying load levels by adding or removing server instances on demand. For an
API gatewayhandling millions of requests per second, this ability to scale linearly with demand is indispensable, ensuring consistent performance even during peak traffic. - Enhanced Reliability and Fault Tolerance: In a stateless environment, the failure of a single server instance does not propagate state loss across the system. Since no client-specific state resides on the server, any server can process any request. If a server crashes, subsequent requests from clients can simply be routed to another healthy server, minimizing disruption and improving the overall resilience of the system. This makes stateless systems inherently more robust against individual component failures, a critical factor for always-on services.
- Simplified Server-Side Logic: Eliminating the need to manage and synchronize server-side session state dramatically simplifies the logic implemented on the server. Developers don't have to concern themselves with session storage, session timeouts, or complex session replication mechanisms across multiple server instances. This reduced complexity in backend code leads to fewer bugs, easier maintenance, and faster development cycles.
- Improved Resource Utilization: Without storing session data, servers consume less memory and processing power per client. This allows individual server instances to handle a greater number of concurrent requests, leading to more efficient utilization of hardware resources. In cloud environments, where resources are billed based on usage, this efficiency can translate into significant cost savings.
- Better Suited for Distributed Environments and Microservices: Statelessness is a natural fit for distributed architectures like microservices. Each microservice can be developed, deployed, and scaled independently, without worrying about maintaining a global session state that crosses service boundaries. This autonomy fosters agility and makes system evolution much more manageable. When an
API gatewayorchestrates multiple microservices, the stateless nature of interactions between the gateway and these upstream services greatly simplifies the gateway's routing and orchestration logic.
Disadvantages of Stateless Architectures
While highly beneficial, statelessness is not without its trade-offs. Understanding these drawbacks is crucial for a balanced architectural decision:
- Increased Request Payload Size: Because each request must carry all necessary information, the size of individual request payloads can be larger. For example, authentication tokens (like JWTs) might be included in every request header, or detailed user preferences might be sent as part of the request body for personalization. While typically small for authentication, for complex workflows requiring significant context, this repeated data transfer can accumulate.
- Potential for Redundancy in Data Transfer: Sending the same pieces of information (e.g., user ID, API key) with every single request, even if they remain constant for a series of interactions, constitutes redundant data transfer. Over a high volume of requests, this can contribute to increased network traffic and potentially higher latency, especially for clients with limited bandwidth or high network costs.
- Increased Client-Side Complexity: Shifting the responsibility of maintaining state from the server to the client means the client-side application or consuming
APIneeds to be smarter. It must manage and store tokens, cookies, or other contextual data, and ensure they are correctly included with every relevant outgoing request. This can complicate client-side development, error handling, and security considerations (e.g., securely storing sensitive tokens). - Performance Overhead for Large Payloads or Frequent Data Transfer: While individual requests might be processed quickly, the cumulative effect of sending larger payloads repeatedly can introduce performance overhead. If an
APIdesign requires substantial state to be exchanged with every call, the overhead of serialization, deserialization, and network transfer might become a bottleneck, especially in latency-sensitive applications or those dealing with very high frequencies of small requests. For anapi gatewaythat simply proxies these larger stateless requests, the overhead might be minimal for the gateway itself, but it still impacts the overall end-to-end performance of the communication.
Statelessness in the Context of API Design
Statelessness is perhaps most famously embodied in the design principles of RESTful APIs, which adhere to the client-server, stateless, cacheable, layered system, uniform interface, and code-on-demand (optional) constraints.
- RESTful APIs as Prime Examples: The stateless constraint is fundamental to REST. Each request from the client to the server must contain all the information needed to understand the request, and the server must not store any client context between requests. This principle enables excellent scalability and simplifies server implementation. Operations are often designed to be idempotent where possible, meaning performing the same operation multiple times has the same effect as performing it once, further enhancing robustness in stateless environments where requests might be retried. The concept of HATEOAS (Hypermedia As The Engine Of Application State) also reinforces statelessness by guiding clients through an
APIusing hyperlinks, rather than relying on server-side session state to remember the client's current position or available actions. - Simplifying Client-Server Interaction: By demanding that each
APIrequest is self-contained, statelessness simplifies the interaction model. Clients don't need to worry about the specific server instance they are communicating with, nor do they need to manage complex session IDs across multipleAPIcalls. This fosters a more decoupled architecture, where client and server can evolve more independently. - Authentication as Client-Managed State: In stateless
APIs, authentication and authorization are typically handled using mechanisms where the client provides credentials with each request. Common patterns include API keys, basic authentication, OAuth 2.0 access tokens, or JSON Web Tokens (JWTs). JWTs are a particularly good fit for stateless APIs: once a client is authenticated, they receive a token containing encrypted information about their identity and permissions. This token is then sent with every subsequent request. The server can validate the token without needing to query a session store, making the authentication process stateless from the server's perspective, as it only validates the token's signature and expiration.
Statelessness in API Gateway Operations
The API gateway sits at the forefront of your backend services, acting as a single entry point for all API consumers. Its design and operational characteristics are heavily influenced by stateless principles, enabling it to fulfill its role effectively as a traffic manager, security enforcer, and request router.
- Core Stateless Functions: An
API gatewayprimarily operates as a stateless intermediary. When it receives a request, it performs a series of operations based solely on the information contained within that request and its configured routing rules. These operations often include:- Proxying and Routing: The
gatewayinspects the incoming request's path, headers, or parameters and routes it to the appropriate backend service instance without holding any long-term session state itself. - Authentication and Authorization: The
gatewaycan validate authentication tokens (e.g., JWTs) included in the request, ensuring the caller is authorized before forwarding the request. This validation typically happens on a per-request basis, making thegateway's role in security stateless regarding client sessions. - Rate Limiting and Throttling: While some rate limiting might involve storing counters, the decision to allow or deny a request is generally made based on the current request's context and global counters, not a specific client session state.
- Transformation: Request and response payloads can be transformed by the
gatewaybased on predefined rules, again, without needing to maintain conversational state.
- Proxying and Routing: The
- Simplifying Load Balancing and Service Discovery: Because the
API gatewaydoesn't maintain client-specific state, it can freely distribute requests to any available backend service instance. This greatly simplifies load balancing algorithms and makes service discovery more efficient. If a backend service instance becomes unavailable, thegatewaycan simply route subsequent requests to another healthy instance, without concerns about breaking client sessions. - Enhanced Performance and Scalability: By operating statelessly, the
API gatewayitself becomes highly scalable. Multiplegatewayinstances can run in parallel, sharing the load. This horizontal scalability is crucial for handling massive inboundAPItraffic, as thegatewaycan elastically expand its capacity to meet demand without requiring complex state synchronization mechanisms betweengatewayinstances. - Example: APIPark's Core Routing and Management: An
API gatewaylike APIPark benefits immensely from stateless principles in its core routing and management functionalities. When APIPark receives an API call, it can instantly apply policies, authenticate, and route the request to the correct backend AI model or REST service, purely based on the information in that single request and its internal configurations. This stateless processing ensures high performance and horizontal scalability, allowing APIPark to handle over 20,000 TPS (Transactions Per Second) with minimal resources and support cluster deployment for large-scale traffic. Its ability to quickly integrate 100+ AI models and provide unifiedAPIinvocation formats relies on this efficient, request-by-request processing model, making it a robust and performant choice for managing diverse AI and RESTAPIs.
Part 2: Embracing Cacheability – The Accelerator of Distributed Systems
While statelessness focuses on the independence of requests, cacheability is about optimizing performance by reducing the need to re-fetch or re-compute data. It introduces the concept of storing copies of frequently accessed information closer to the consumer, thereby speeding up subsequent accesses and reducing the load on upstream services.
Definition of Cacheable: Storing for Speed
Caching, in its essence, is the process of storing data in a temporary storage area, known as a cache, so that future requests for that data can be served faster than by retrieving it from its primary source. This primary source could be a database, another service, a file system, or even a remote API. The fundamental purpose of caching is to reduce latency, improve throughput, and decrease the operational burden on backend systems.
A resource is considered "cacheable" if a client or an intermediary can store a copy of its representation and use that copy to fulfill subsequent identical requests without needing to re-contact the origin server. This implies that the resource's state is relatively stable or that the system is willing to tolerate a degree of data staleness for the sake of performance. For APIs, cacheability often applies to idempotent read operations (like GET requests) for data that doesn't change frequently. When an API gateway or a client determines a response is cacheable, it saves that response. The next time the exact same request comes in, instead of forwarding it to the backend API, the gateway or client serves the stored copy, significantly reducing response time and backend load.
Core Principles and Characteristics of Cacheable Architectures
Cacheable architectures are built upon several guiding principles and exhibit distinct characteristics:
- Data Duplication and Proximity: The core idea is to create copies of data and place them geographically or logically closer to where they are consumed. This reduces the network distance and the number of hops required to access the data. Caches can exist at multiple layers: client-side (browser cache), proxy cache (
API gateway, CDN), server-side (in-memory cache, distributed cache), and even database-level caches. - Temporal Locality: This principle suggests that if a piece of data has been accessed recently, it is likely to be accessed again soon. Caches exploit this by keeping recently used items readily available, assuming future requests will target them.
- Spatial Locality: This principle states that if a particular memory location is accessed, then it is likely that nearby memory locations will be accessed soon. In caching, this might mean pre-fetching related data or caching entire blocks of data even if only a portion was initially requested.
- Cache Invalidation Strategies: The most challenging aspect of caching is ensuring that cached data remains fresh and consistent with the original source. Various strategies are employed:
- Time-To-Live (TTL): Data is cached for a predefined duration, after which it is considered stale and must be re-fetched.
- ETag (Entity Tag): A unique identifier (hash) for a specific version of a resource. Clients can send the ETag in a subsequent request (If-None-Match header). If the ETag matches, the server returns a 304 Not Modified, signaling the client to use its cached copy.
- Last-Modified: Similar to ETag, but uses a timestamp. Clients send an If-Modified-Since header.
- Push/Pull Invalidation: Origin servers can "push" invalidation messages to caches when data changes, or caches can periodically "pull" checks for freshness.
- Trade-offs: Stale Data Risk vs. Performance Gain: Caching inherently involves a trade-off. While it dramatically improves performance, it introduces the risk of serving outdated or "stale" data if invalidation strategies are not robust or if data changes very rapidly. The acceptable level of staleness is a critical design consideration, varying significantly between different types of data and applications.
These principles guide the implementation of caching layers, transforming how data flows through a system and impacting user experience and operational costs.
Advantages of Cacheable Architectures
Integrating caching mechanisms into an API or system architecture yields a multitude of significant benefits:
- Dramatic Performance Enhancement: This is the primary driver for adopting caching. By serving requests from a cache, the data retrieval process bypasses slower operations such as database queries, complex computations, or remote
APIcalls. This significantly reduces latency, leading to faster response times for clients and a smoother, more responsive user experience. ForAPIconsumers, particularly those with high performance demands, milliseconds saved on each request can translate into substantial gains. - Reduced Load on Origin Servers: Every request served from a cache is a request that doesn't reach the backend
APIor database. This offloads a substantial amount of work from the origin servers, freeing up their resources (CPU, memory, database connections) to handle more complex or dynamic requests. During traffic spikes, a well-implemented cache can absorb a large portion of the load, preventing backend services from becoming overwhelmed and maintaining system stability. AnAPI gatewaywith caching capabilities is invaluable in this regard, acting as a buffer against surges inAPIcalls. - Improved Scalability and Resilience: By reducing the load on backend services, caching effectively extends the capacity of the entire system. You can handle more concurrent users or requests with the same amount of backend infrastructure. Furthermore, if a backend service temporarily goes offline or experiences performance degradation, a cache can continue to serve stale (but possibly acceptable) data, providing a degree of resilience and graceful degradation during outages.
- Cost Savings: Reduced load on origin servers often translates directly into lower infrastructure costs. Fewer servers or smaller server instances might be needed, and less bandwidth might be consumed if the cache is closer to the client (e.g., CDN). In cloud environments, where compute and egress traffic are billed, these savings can be substantial over time.
- Reduced Network Traffic and Bandwidth Usage: When a cache serves a response, it typically does so over a shorter network path (e.g., from the browser's local cache or an
API gatewaywithin the same data center) than if the request had to travel all the way to the origin server. This reduces overall network traffic and bandwidth consumption, particularly beneficial for mobile clients or applications operating in regions with high data transfer costs.
Disadvantages of Cacheable Architectures
Despite its powerful advantages, caching introduces its own set of challenges that must be carefully managed:
- Cache Coherency and Stale Data Issues: The most notorious challenge in caching is maintaining cache coherency – ensuring that the data stored in the cache is consistent with the data on the origin server. If the origin data changes but the cache is not updated or invalidated, clients will receive stale data. This can lead to incorrect application behavior, poor user experience, or even critical errors in systems requiring high data fidelity. Developing robust cache invalidation strategies is often complex and error-prone.
- Increased System Complexity: Implementing and managing a caching layer adds significant complexity to the system architecture. Decisions must be made regarding cache size, eviction policies (e.g., LRU, LFU), key generation, data serialization, and invalidation mechanisms. Distributed caches introduce further complexity with network communication, consistency protocols, and potential single points of failure. This complexity can increase development time and require specialized expertise to maintain.
- Potential for Initial Cache Miss Latency: While subsequent requests are fast, the very first request for a particular piece of data (a "cache miss") will incur the full latency of fetching from the origin server, plus the overhead of writing to the cache. In some cases, if the caching layer itself adds significant overhead, a cache miss might even be slightly slower than a direct request to the origin, though this is usually outweighed by subsequent cache hits.
- Resource Consumption for the Cache Itself: Caches, especially large ones, consume memory, disk space, and potentially CPU cycles for management tasks (e.g., eviction, replication). While they reduce load on origin servers, they introduce resource requirements for the caching infrastructure itself. For highly dynamic data with low hit rates, the overhead of caching might outweigh its benefits.
- Security Concerns with Cached Sensitive Data: Caching sensitive information (e.g., personal identifiable information, financial data) requires extreme caution. If a cache is compromised or misconfigured, sensitive data could be exposed. Appropriate encryption, access controls, and strict TTLs (or outright exclusion from caching) are essential for such data types.
Cacheability in the Context of API Design
Designing APIs with cacheability in mind is a critical aspect of building high-performance web services. HTTP, the protocol underlying most APIs, provides extensive mechanisms for controlling caching.
- Leveraging HTTP Caching Headers: The HTTP specification includes powerful headers specifically designed to manage caching:
- Cache-Control: This header is the most versatile, allowing both the server and client to specify caching policies. Directives like
max-age(how long a resource is considered fresh),no-cache(revalidate before using),no-store(never cache),public(any cache can store),private(only client cache can store), ands-maxage(for shared caches like CDNs/API gateways) provide fine-grained control. - Expires: An older header specifying an absolute expiry date/time.
Cache-Control: max-agegenerally supersedes it. - Pragma: An older, less flexible header, primarily
Pragma: no-cacheto request fresh data. - ETag (Entity Tag) and Last-Modified: These are used for revalidation. When a client makes a subsequent request for a cached resource, it can send
If-None-Matchwith theETagorIf-Modified-Sincewith theLast-Modifieddate. The server checks these. If the resource hasn't changed, it responds with a304 Not Modifiedstatus, telling the client to use its cached copy, saving bandwidth and processing.
- Cache-Control: This header is the most versatile, allowing both the server and client to specify caching policies. Directives like
- Designing APIs for Cacheability:
- GET Requests are Ideal:
APIs that represent read-only operations, typically performed via HTTP GET, are the prime candidates for caching. GET requests are inherently idempotent and retrieve data without causing side effects on the server. - Idempotent Operations: While caching is most common for GET, other idempotent operations (like PUT, DELETE) can sometimes be cached, though with more careful consideration of invalidation.
- Avoid Caching Dynamic or Personalized Data: Responses that contain highly dynamic, user-specific, or frequently changing data (e.g., shopping cart contents, real-time stock quotes) are generally poor candidates for caching, or require very short TTLs.
- Consistent URIs: Caches key responses based on the request URI. Consistent, predictable URIs for the same resource are essential for effective caching. Variations in query parameters that don't change the content should be normalized if possible.
- GET Requests are Ideal:
- When to Use Caching for APIs:
- Static or Semi-Static Data: Product catalogs, configuration settings, country lists, currency exchange rates (if updated infrequently).
- Frequently Accessed Reference Data: Common lookup tables, user profiles that are mostly read-only, blog posts.
- Expensive Computations: Results of complex analytics queries or AI model inferences that are time-consuming to generate but don't change often.
Cacheability in API Gateway Operations
The API gateway is an ideal location to implement a caching layer, sitting between clients and backend services. Its position makes it a powerful tool for improving performance and protecting backend systems.
API Gatewayas a Crucial Caching Layer: AnAPI gatewaycan serve as a shared, centralized cache for all clients accessing a particularAPI. This is particularly effective for publicAPIs orAPIs consumed by many different internal applications. By caching responses at thegateway, multiple clients can benefit from the same cached data, dramatically reducing the load on backend services and improving overall system responsiveness. This shared cache can be more effective than individual client-side caches, as it can serve a broader set of requests.- Configuration of Caching Policies: Modern
API gateways provide extensive configuration options for caching:- Time-To-Live (TTL): Define how long responses should remain in the cache before being considered stale.
- Key Generation: Configure how the cache key is generated from incoming requests (e.g., based on URI, specific headers, query parameters). This ensures that distinct requests receive distinct cached responses.
- Varying Responses: Specify headers that, if present, mean the response might vary (e.g.,
Accept-Language,User-Agent). Thegatewaycan store multiple cached versions of the same resource based on these varying headers. - Cache Invalidation: Implement mechanisms to explicitly invalidate cached items when the underlying data changes in the backend. This might involve an
APIcall to thegateway's admin interface or event-driven invalidation.
- Benefits for
API Gateways in Managing Traffic and Improving Responsiveness:- Traffic Spike Management: Caching allows the
API gatewayto absorb sudden bursts of traffic for popularAPIendpoints without overwhelming backend services. - Reduced Latency for End-Users: Serving responses from the
gatewaycache significantly reduces the round-trip time for clients, leading to a snappier user experience. - Backend Protection: Acts as a protective layer, shielding backend
APIs from excessive requests, especially for read-heavy operations, enhancing their stability and reliability. - Optimizing Cloud Costs: By reducing the number of requests reaching expensive backend compute instances or databases,
gatewaycaching can lead to substantial cost savings in cloud environments.
- Traffic Spike Management: Caching allows the
- Leveraging
APIParkfor Enhanced Performance with Caching: An advancedAPI gatewaylike APIPark could strategically leverage caching to boost performance, especially when managing AI models. For example, frequently accessed metadata about AI models, configuration settings, or even the results of common, deterministic AI inferences (like sentiment analysis for widely known phrases) could be cached at thegatewaylayer. This would reduce the number of calls to the actual AI service, decrease latency, and lower computational costs. APIPark's unifiedAPIformat for AI invocation and its ability to encapsulate prompts into RESTAPIs make it an excellent candidate for implementing intelligent caching strategies. By providing detailedAPIcall logging and powerful data analysis, APIPark also offers the tools to monitor cache hit rates and identify further opportunities for optimization, ensuring the most efficient and performant delivery of both AI and RESTAPIservices.
APIPark is a high-performance AI gateway that allows you to securely access the most comprehensive LLM APIs globally on the APIPark platform, including OpenAI, Anthropic, Mistral, Llama2, Google Gemini, and more.Try APIPark now! 👇👇👇
Part 3: The Interplay and Key Differences: Stateless vs. Cacheable
While both statelessness and cacheability are foundational principles for building robust distributed systems, they serve different primary objectives and interact in complex, often complementary, ways. It's crucial to understand their distinctions and how they can be combined to achieve optimal architectural outcomes.
Fundamental Distinction: Purpose and Scope
The most critical difference lies in their core purpose:
- Stateless: Primarily concerns the independence of individual requests regarding server-side session state. Its goal is to eliminate any server-side memory of past client interactions, promoting horizontal scalability, fault tolerance, and simplicity in server logic. A stateless system doesn't necessarily mean data isn't stored anywhere; it just means the server processing the request doesn't hold the client's session-specific state between requests. Any required state is either client-managed or retrieved from a shared, highly available (and often eventually consistent) data store.
- Cacheable: Primarily concerns performance optimization through data retention. Its goal is to reduce latency, decrease server load, and conserve bandwidth by storing copies of data that are likely to be requested again. Cacheability doesn't dictate how requests are processed in terms of state, but rather where the data for those requests might originate.
It's vital to recognize that these concepts are not mutually exclusive. In fact, they often work together to create highly performant and scalable systems. A system can be stateless (servers don't remember client sessions) and cacheable (responses can be stored and reused). For instance, a RESTful API is designed to be stateless, yet many of its GET endpoints are highly cacheable. An API gateway operates largely stateless but can incorporate powerful caching mechanisms.
Architectural Implications
The choices between or combining stateless and cacheable patterns have profound implications across several architectural dimensions:
- Scalability: Both contribute to scalability, but in distinct ways.
- Statelessness: Enables horizontal scalability by making it easy to add more server instances without complex state synchronization. Any server can handle any request.
- Cacheability: Contributes to scalability by offloading backend servers, allowing them to handle a greater number of unique or dynamic requests. It essentially provides a performance buffer.
- Complexity:
- Statelessness: Generally simplifies server logic by removing the need for server-side session management, but can increase client-side complexity in managing and transmitting state with each request.
- Cacheability: Adds complexity to the system, primarily around cache management, invalidation strategies, and ensuring data consistency. Deciding what to cache, for how long, and how to invalidate it correctly is notoriously difficult ("the two hardest things in computer science are cache invalidation and naming things").
- Data Consistency and Freshness:
- Statelessness: Guarantees that data is always fresh and directly from the origin (or whatever the request resolves to at that moment), as there's no intermediate copy introducing potential staleness.
- Cacheability: Introduces the potential for stale data. While this risk can be mitigated with robust invalidation strategies, it's an inherent trade-off of performance against absolute freshness. The acceptable degree of staleness depends entirely on the application's requirements.
- Performance:
- Statelessness: Can have higher per-request overhead due to the need to transmit all context with each request (e.g., larger JWTs), but offers excellent throughput when scaled horizontally. The first request is as fast as any subsequent one, provided no external state lookup.
- Cacheability: Dramatically improves performance for subsequent requests (cache hits) by serving them from a fast, local store. Initial requests (cache misses) might have slightly higher latency due to caching overhead.
When to Choose Which (or Both): Strategic Application
The decision to favor statelessness, cacheability, or, most commonly, a combination of both, depends heavily on the specific requirements and characteristics of the API and the broader system.
Prioritize Statelessness When:
- Building High-Throughput, Distributed Systems: For microservices architectures, cloud-native applications, or any system requiring massive horizontal scalability, statelessness is the default choice. It ensures that load can be distributed evenly across numerous instances.
- Designing APIs with Dynamic, Personalized Data: If
APIresponses are highly individualized for each user and change frequently (e.g., user-specific dashboards, real-time transaction feeds), attempting to cache them extensively would be ineffective or lead to severe cache coherency issues. - Handling Security-Sensitive Transactions: For operations where intermediate state should not reside on any server (e.g., payment processing steps, highly sensitive data modifications), statelessness ensures that each transaction is self-contained and auditable without relying on brittle session management. Authentication via tokens (JWTs) fits perfectly here, with tokens being validated per request without server-side session storage.
- Simplifying Backend Logic: For development teams aiming for simpler, more predictable server code, statelessness reduces the cognitive load associated with managing complex session states and their distribution.
Prioritize Cacheability When:
- Dealing with Static or Semi-Static Data: Resources that change infrequently (e.g., product images, static web pages, configuration files, country lists) are prime candidates for long-term caching.
- Building Read-Heavy APIs: If your
APIserves a large number of GET requests for the same data (e.g., public data, popular blog posts, common search results), caching can dramatically reduce the load on your backend databases and services. - Reducing Load on Expensive Backend Computations: If certain
APIcalls involve time-consuming processes, like complex database joins, externalAPIcalls, or AI model inferences (as in APIPark's use case for AI models), caching the results for a reasonable period can significantly improve performance and reduce resource consumption. - Improving User Experience by Reducing Latency: For geographically dispersed users or applications sensitive to network latency, caching can bring data closer to the user, providing a faster and more fluid experience.
The Power of Both: Complementary Forces
The most common and powerful approach in modern API architectures is to leverage both statelessness and cacheability.
- Stateless Core, Cacheable Edges: Design your core backend services and
APIs to be stateless. This ensures they are inherently scalable and resilient. Then, introduce caching layers at appropriate points, such as within theAPI gateway, at a CDN, or even on the client-side, for data that benefits from it. - Smart
API Gateways: AnAPI gatewaylike APIPark can act as a stateless router and policy enforcer, handling authentication and authorization on a per-request basis. Simultaneously, it can be configured to cache responses from backend services (especially AI model inferences or staticAPIdata), providing the performance benefits of caching without compromising the scalability benefits of stateless backends. This hybrid approach allows the system to remain highly scalable while optimizing for common access patterns. - HTTP Protocol Design: The HTTP protocol itself is a testament to this synergy, allowing for stateless client-server interactions while providing extensive headers for intelligent caching.
Table Comparison: Stateless vs. Cacheable
To crystalize the differences, here's a comparative overview:
| Feature / Aspect | Stateless | Cacheable |
|---|---|---|
| Primary Goal | Request independence, horizontal scalability, resilience | Performance improvement, reduced backend load, bandwidth savings |
| State Management | No server-side session state; context in each request or client-managed | Stores copies of data to serve future requests faster; manages invalidation |
| Request Payload | Can be larger (full context per request), often includes authentication tokens | Can be smaller for subsequent requests (if data is cached) |
| Data Freshness | Always fresh (retrieved from origin for each request) | Potential for stale data (unless robust invalidation is used) |
| Complexity | Simpler server logic; client manages context/tokens | Adds complexity for cache management, invalidation, and consistency |
| Scalability | Enables effortless horizontal scaling of servers and microservices | Offloads backend services, improving their effective scalability and throughput |
| Typical Use Case | RESTful APIs, microservices, transactional services, OAuth/JWT authentication | Static content, read-heavy APIs, reference data, results of expensive computations (e.g., AI inferences) |
Impact on API Gateway |
Simplifies routing, load balancing, per-request policy enforcement | Reduces calls to backend, faster responses, protects backend from overload |
| Core Mechanism | Self-contained requests; no memory of past client interactions | Data duplication; temporary storage near consumption point |
| HTTP Headers | N/A (inherent architectural property) | Cache-Control, Expires, ETag, Last-Modified |
Understanding this table highlights that statelessness defines the behavior of the server with respect to sessions, while cacheability defines the strategy for optimizing data access. Both are powerful, and their combined application forms the bedrock of modern, high-performance distributed systems.
Part 4: Practical Considerations and Best Practices for API and API Gateway Design
Designing and implementing APIs and their managing API gateways effectively requires a thoughtful application of both stateless and cacheable principles. Moving beyond theoretical understanding, these practical considerations guide developers and architects toward building systems that are not only robust but also performant and maintainable.
Design for Statelessness First
The default posture for modern API design should be statelessness. This foundational choice sets the stage for a scalable and resilient architecture.
- Embrace RESTful Principles: Adhere to the core tenets of REST, ensuring that each
APIrequest is self-contained. This means avoiding server-side sessions for managing conversational state. - Use Tokens for Authentication: For authentication, move away from cookie-based, stateful sessions. Instead, adopt stateless tokens like JSON Web Tokens (JWTs). Once issued, a JWT contains all necessary authentication and authorization information, allowing the
API gatewayor backend service to validate it on each request without needing to consult a shared session store. This significantly simplifies scaling and load balancing for your authentication services and thegatewayitself. - Pass Context Explicitly: Any information required for an
APIcall should be explicitly passed in the request itself, whether in headers, query parameters, or the request body. This ensures that any service instance can process the request independently. - Consider Idempotent Operations: Design
APIoperations to be idempotent whenever possible. This means that making the same request multiple times has the same effect as making it once. While not strictly a statelessness requirement, it greatly enhances the robustness of stateless systems, where network issues might cause clients orAPI gateways to retry requests.
Identify Cacheable Resources and Implement Effective Strategies
Once the stateless foundation is in place, the next step is to strategically identify and implement caching for resources that can benefit from it.
- Profile Your
APIUsage: Analyze yourAPItraffic patterns to identify endpoints that are read-heavy, return relatively static data, or involve expensive computations. These are your prime candidates for caching.APIPark's powerful data analysis features, which display long-term trends and performance changes, would be invaluable here for identifying frequently accessed endpoints or AI model responses that could benefit from caching. - Leverage HTTP Caching Headers: Make full use of HTTP caching headers (
Cache-Control,ETag,Last-Modified) in yourAPIresponses. This allows clients, CDNs, andAPI gateways to intelligently cache and revalidate resources.Cache-Control: public, max-age=3600is a good starting point for broadly cacheable resources. - Utilize
API GatewayCaching Capabilities: Configure yourAPI gatewayto cache responses for identifiedAPIs. AnAPI gatewaycan offer sophisticated caching policies, including:- Configurable TTLs: Set appropriate Time-To-Live values based on how frequently the underlying data changes.
- Custom Cache Keys: Define how the cache key is generated (e.g., from
URI, specific query parameters, request headers) to ensure proper cache segmentation. - Conditional Caching: Cache only specific
HTTPmethods (e.g., GET) or status codes. - Active Invalidation: Implement mechanisms for programmatically invalidating cached items when backend data changes, rather than waiting for TTL expiration. This can involve webhook notifications from backend services to the
gateway.
- Consider Distributed Caches: For very large-scale systems or across multiple data centers, a distributed cache (e.g., Redis, Memcached) might be necessary to share cached data across multiple
API gatewayinstances or backend services.
Security Implications
Both statelessness and cacheability have important security considerations:
- Stateless Authentication: While JWTs are great for statelessness, ensure they are signed with a strong secret, have appropriate expiration times, and are stored securely on the client-side (e.g., in
HTTP-onlycookies or local storage with care). Revocation of tokens can be challenging in a purely stateless system, often requiring blacklisting or short TTLs. YourAPI gatewayplays a crucial role in validating these tokens on every request. - Caching Sensitive Data: Be extremely cautious about caching sensitive or personalized data. In many cases, it should not be cached at all, or if absolutely necessary, only with very short TTLs, strong encryption, and strict access controls. Ensure caches are secured against unauthorized access.
APIPark's independentAPIand access permissions for each tenant, and its requirement forAPIresource access approval, provide layers of security that can help mitigate risks when managing access to sensitiveAPIs, regardless of caching strategies.
Monitoring and Observability
Regardless of your architectural choices, robust monitoring and observability are non-negotiable.
- Track Key Metrics:
- Cache Hit/Miss Ratios: Crucial for understanding the effectiveness of your caching strategy. A low hit ratio indicates that caching might not be providing significant benefits, or that your invalidation strategy is too aggressive.
- Latency for Cached vs. Origin Requests: Compare response times to quantify the performance gain from caching.
- Backend Load Reduction: Monitor the load on your backend services to see the impact of
API gatewaycaching. - Error Rates: Track errors across both stateless
APIcalls and cache interactions to quickly identify issues.
- Leverage
API GatewayFeatures:APIParkoffers detailedAPIcall logging, recording every detail of eachAPIcall, and powerful data analysis features. These are invaluable for tracing and troubleshooting issues, understanding system stability, identifying performance bottlenecks, and optimizing both stateless and cacheableAPIbehavior. By analyzing historical call data, businesses can predict trends and perform preventive maintenance, ensuring the health and efficiency of theirAPIecosystem.
Choosing the Right Tools
The choice of tools, particularly your API gateway, is critical for implementing these principles effectively.
API Gatewayas an Enabler: A robustAPI gatewayis fundamental for managing modernAPIs. It acts as the control plane that can enforce stateless principles (e.g., JWT validation, routing) and implement sophisticated caching strategies (e.g., response caching, conditional caching).- Example: APIPark's Role: APIPark is an open-source AI gateway and
APImanagement platform designed to help developers and enterprises manage, integrate, and deploy AI and REST services. Its features directly support the principles discussed:- Unified
APIFormat for AI Invocation: This streamlines stateless interactions with diverse AI models. - End-to-End
APILifecycle Management: Helps define and enforce statelessAPIcontracts and manage traffic forwarding, which is inherently stateless. - Performance Rivaling Nginx: Demonstrates its capability to handle high throughput in a stateless manner.
- Open-Source & Commercial Support: Offers flexibility, allowing startups to utilize basic features and enterprises to access advanced features like potentially more sophisticated caching and management capabilities, along with professional technical support.
- Unified
By strategically leveraging a powerful API gateway like APIPark, organizations can effectively implement both stateless and cacheable patterns, achieving optimal performance, scalability, and security for their API landscape.
Conclusion: The Synergy of Statelessness and Cacheability in Modern API Ecosystems
The journey through the realms of statelessness and cacheability reveals two distinct yet profoundly complementary architectural paradigms that are indispensable for building resilient, scalable, and high-performance API ecosystems. Statelessness, with its emphasis on independent requests and the absence of server-side session state, lays the groundwork for horizontal scalability and fault tolerance, making systems inherently more robust and easier to manage in distributed environments. It is the bedrock upon which microservices and the modern web thrive, ensuring that any server instance can handle any client request without context entanglement.
Cacheability, on the other hand, is the quintessential performance accelerator. By intelligently storing copies of data closer to the consumer, it dramatically reduces latency, offloads backend services, and optimizes resource utilization. It introduces a calculated trade-off between absolute data freshness and blazing speed, a trade-off that, when managed wisely, yields immense benefits in user experience and operational cost savings.
The true mastery in API architecture lies not in choosing one over the other, but in understanding their synergy. Modern APIs and the sophisticated API gateways that manage them—such as APIPark—are often designed to be fundamentally stateless, allowing for unparalleled scalability and simplicity in their core routing and processing. Simultaneously, these very same systems ingeniously incorporate caching layers to optimize access to frequently requested or expensive-to-generate data, transforming potential bottlenecks into sources of rapid response.
From the API designer carefully crafting HTTP headers to the API gateway administrator configuring intelligent caching policies, both stateless and cacheable principles demand attention to detail and a clear understanding of their respective implications. By embracing statelessness as the default for request handling and strategically applying caching where performance gains outweigh the complexities of cache coherency, developers and architects can engineer APIs that are not just functional, but also exceptional in their performance, reliability, and cost-efficiency. In an era where APIs are the lifeblood of digital innovation, mastering these foundational concepts is no longer an option, but a critical imperative for success.
5 Frequently Asked Questions (FAQs)
1. What is the fundamental difference between a stateless API and a cacheable API?
The fundamental difference lies in their primary concerns. A stateless API is one where the server does not store any client-specific session data or context between requests. Each request from the client must contain all the information necessary for the server to process it independently. Its goal is primarily to ensure horizontal scalability and simplify server logic. A cacheable API refers to an API whose responses can be stored temporarily (cached) by clients or intermediate proxies (like an API gateway) to fulfill future identical requests faster. Its goal is primarily to improve performance, reduce latency, and decrease the load on backend servers by reusing previously fetched data. An API can be both stateless and cacheable.
2. Why is statelessness considered crucial for API gateways and microservices architectures?
Statelessness is crucial because it enables massive horizontal scalability and enhances fault tolerance. In a stateless system, any instance of a service or API gateway can handle any incoming request, as no single instance holds client-specific session state. This allows for easy distribution of load, dynamic scaling up or down of resources, and seamless failover if an instance goes down. For API gateways, this means they can efficiently route millions of requests to diverse backend services without becoming a bottleneck due to state management, making them highly resilient and performant.
3. What are the main challenges associated with implementing caching in APIs?
The primary challenge of caching is cache coherency, which refers to keeping the cached data consistent and up-to-date with the original source data. If the original data changes but the cache isn't updated or invalidated, clients might receive stale information, leading to incorrect application behavior. Implementing robust cache invalidation strategies (e.g., using TTL, ETags, or active invalidation mechanisms) is complex. Other challenges include managing the increased system complexity (cache size, eviction policies, distributed caching), potential initial cache miss latency, and securely handling sensitive data in the cache.
4. Can an API be both stateless and cacheable? If so, how do these concepts interact?
Yes, an API can absolutely be both stateless and cacheable, and this is a common and powerful combination in modern architectures. Statelessness defines how the API server behaves regarding client sessions (not retaining state), while cacheability defines whether an API's responses can be temporarily stored for performance. For example, a RESTful API is typically stateless, meaning each request is independent. However, its GET endpoints, which retrieve data and cause no side effects, are often designed to be highly cacheable using HTTP caching headers. The API gateway manages this by performing stateless routing and authentication, while also caching responses from these cacheable endpoints to further improve performance and reduce backend load.
5. How does a product like APIPark leverage these principles to manage AI and REST APIs?
APIPark, as an AI gateway and API management platform, inherently benefits from and implements both principles. Its core routing and API management capabilities are built on stateless principles, allowing it to process each API call independently, validate tokens, and route requests to backend AI models or REST services without holding long-term session state. This ensures APIPark's high performance (e.g., 20,000+ TPS) and horizontal scalability for handling large traffic volumes. Simultaneously, APIPark can strategically leverage cacheability by, for example, caching results of common AI model inferences, static API responses, or frequently accessed metadata about AI models. This reduces calls to backend services, decreases latency for clients, and optimizes resource utilization, further enhanced by APIPark's detailed call logging and data analysis features to identify optimal caching opportunities.
🚀You can securely and efficiently call the OpenAI API on APIPark in just two steps:
Step 1: Deploy the APIPark AI gateway in 5 minutes.
APIPark is developed based on Golang, offering strong product performance and low development and maintenance costs. You can deploy APIPark with a single command line.
curl -sSO https://download.apipark.com/install/quick-start.sh; bash quick-start.sh

In my experience, you can see the successful deployment interface within 5 to 10 minutes. Then, you can log in to APIPark using your account.

Step 2: Call the OpenAI API.