Optimizing Asynchronous Data Sending to Two APIs
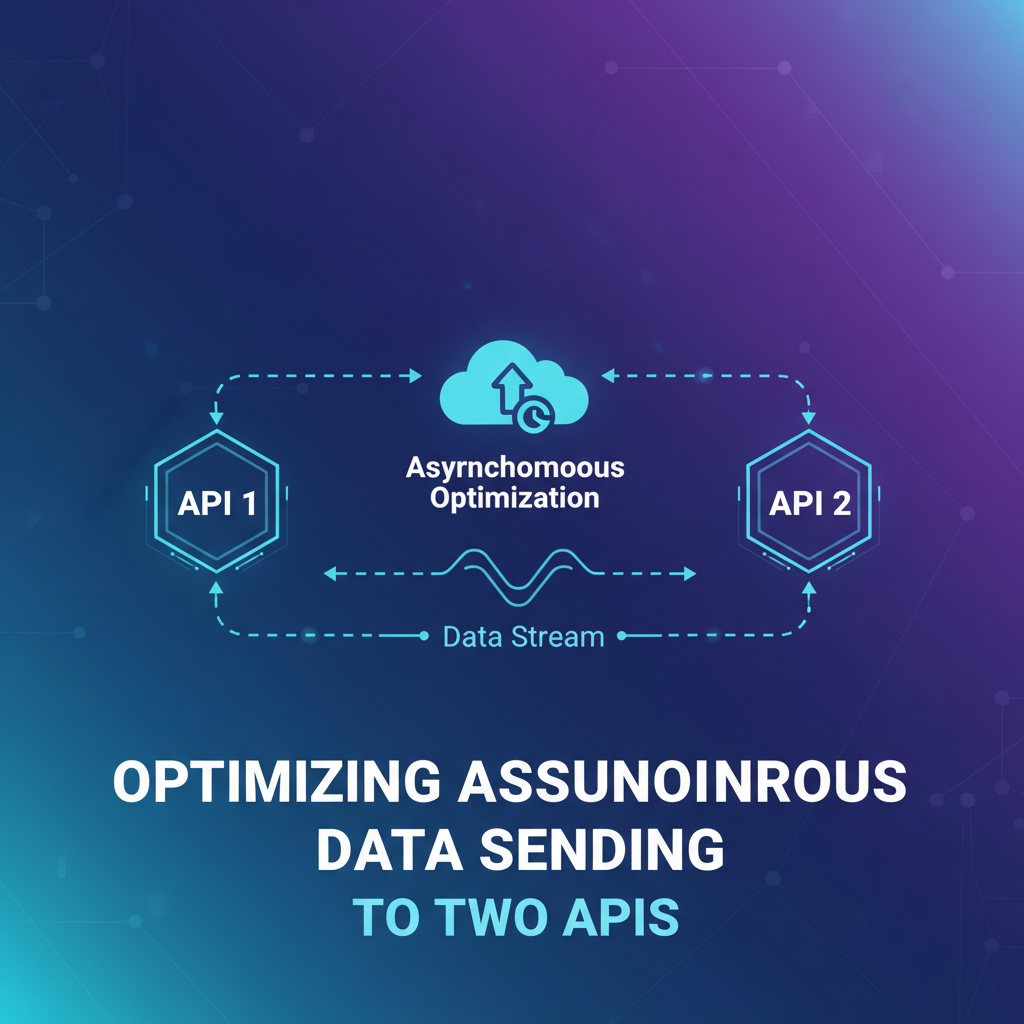


In the rapidly evolving landscape of modern software architecture, the need to integrate disparate systems and services is ubiquitous. Organizations increasingly rely on microservices, serverless functions, and third-party APIs to build robust, scalable, and feature-rich applications. A common and often critical requirement is the ability to send data to multiple external endpoints simultaneously or near-simultaneously. While the concept might seem straightforward at first glance, the intricacies of ensuring reliability, consistency, and performance when dispatching asynchronous data to two distinct APIs present a multifaceted challenge that demands careful architectural consideration and meticulous implementation. This article delves deep into the strategies, patterns, and best practices essential for optimizing asynchronous data sending to dual API endpoints, ensuring operational excellence, data integrity, and system resilience in complex distributed environments.
The Imperative of Asynchronous Data Sending in Modern Architectures
Modern applications are characterized by their distributed nature, high concurrency requirements, and the expectation of seamless user experiences. In such environments, synchronous operations, where a system waits for a response before proceeding, can become a significant bottleneck, leading to degraded performance, reduced scalability, and increased latency. This is precisely where asynchronous data sending emerges as a pivotal architectural pattern, offering a paradigm shift that liberates calling services from the immediate need to await responses, thereby fostering greater responsiveness and resource efficiency.
Asynchronous processing allows a service to dispatch a request or a message and immediately move on to other tasks, with the understanding that the response or outcome will be handled at a later time, often by a separate process or callback mechanism. This approach is fundamental to building reactive systems that can gracefully handle varying loads, tolerate failures, and remain responsive under stress. Common mechanisms that underpin asynchronous data sending include message queues (such as Kafka, RabbitMQ, or Amazon SQS), event buses, and background job processors. These tools provide buffering capabilities, enabling producers to publish messages without being constrained by the processing speed of consumers, and offering robust retry mechanisms that enhance fault tolerance. The core benefits derived from embracing asynchronous communication are manifold: improved system responsiveness, enhanced scalability as components can be scaled independently, better resource utilization, and increased resilience to transient failures in downstream services.
The scenario of sending data to two distinct APIs, however, introduces an additional layer of complexity. This need frequently arises in various business contexts. For instance, an e-commerce platform might need to update its internal inventory management API and simultaneously send order details to a third-party logistics API. A financial service might dispatch a transaction record to its internal ledger system while also forwarding details to a fraud detection API. User registration might involve storing user profiles in one API and triggering a welcome email via a notification API. In each of these cases, the operations are often critical, and the failure of one should ideally not impede the success of the other, or at least be handled gracefully without data loss or inconsistency. The challenges associated with this dual API interaction include managing disparate latency expectations, handling independent failure modes, ensuring data consistency across both endpoints, and orchestrating retries effectively. Therefore, understanding the nuances of asynchronous communication and the specific difficulties it presents when extended to multiple destinations is the first crucial step toward building an optimized and reliable solution.
Navigating the Labyrinth: Core Challenges in Dual API Asynchronous Operations
Sending data to a single API asynchronously already demands careful attention to error handling and retries. When the target expands to two distinct APIs, the complexity scales exponentially, introducing a unique set of challenges that, if not adequately addressed, can lead to data inconsistencies, operational nightmares, and significant system instability. A deep understanding of these challenges is paramount for designing resilient and efficient solutions.
Idempotency: The Guard Against Duplication
One of the most insidious problems in distributed systems, especially those employing retries, is the risk of duplicate operations. Idempotency refers to the property of an operation that, when executed multiple times with the same parameters, produces the same result as if it were executed only once. For example, setting a value is idempotent, but incrementing a counter is not. In our scenario, imagine sending an "order created" message to two APIs. If the call to API A succeeds but API B fails, and we retry the entire operation, API A might receive the "order created" message again. Without idempotency, this could lead to duplicate orders, incorrect inventory deductions, or redundant notifications. Implementing idempotency typically involves the use of unique request identifiers (idempotency keys) that the receiving API uses to detect and discard duplicate requests within a certain time window. Each API must be designed or adapted to respect these keys, ensuring that even if a message is processed multiple times, the state change only occurs once.
Atomicity and Consistency: The Holy Grail of Distributed Transactions
Ensuring that both operations either succeed or fail together, known as atomicity, is a cornerstone of data integrity. In a single-system environment, this is often achieved through database transactions. However, across two independent APIs, achieving true atomicity is notoriously difficult due to the "distributed transactions problem." A traditional two-phase commit (2PC) protocol, while offering strong consistency guarantees, is often considered too heavy and blocking for high-performance, asynchronous microservices architectures. It introduces a single point of failure and can significantly reduce availability.
Instead, modern distributed systems often lean towards the Saga pattern. A Saga is a sequence of local transactions, where each transaction updates data within a single service and publishes an event to trigger the next step in the Saga. If any local transaction fails, the Saga executes compensating transactions to undo the changes made by preceding successful transactions, effectively rolling back the entire distributed operation. This pattern allows for eventual consistency, which is often acceptable and even preferred in highly scalable systems, but requires careful design of compensating actions and robust error handling logic to manage the intermediate inconsistent states. The choice between strong consistency (like 2PC, if even feasible) and eventual consistency (like Saga) largely depends on the specific business requirements and tolerance for temporary inconsistencies.
Error Handling and Retries: Forging Resilience in the Face of Failure
The asynchronous nature of the operation means that failures are not immediately apparent to the initiating service, and they can occur independently for each target API. A robust error handling strategy must encompass:
- Differentiated Retry Policies: One API might be more reliable or have a lower latency profile than the other. Therefore, applying the same retry policy to both might be suboptimal. API A might require aggressive retries with a short backoff, while API B might need a longer delay due to its inherent slowness or external dependencies.
- Exponential Backoff: This widely adopted strategy increases the wait time between retries exponentially, preventing a client from overwhelming a struggling service and giving it time to recover. Adding jitter (a random component) to the backoff helps prevent the "thundering herd" problem, where multiple retrying clients hit the service simultaneously.
- Circuit Breakers: Inspired by electrical circuit breakers, this pattern prevents an application from repeatedly invoking a failing service. If a service consistently fails, the circuit breaker "trips," opening the circuit and redirecting subsequent calls to a fallback mechanism or returning an error immediately, allowing the failing service to recover without additional load. After a period, the circuit enters a "half-open" state, allowing a limited number of test requests to determine if the service has recovered.
- Dead Letter Queues (DLQs): Messages that cannot be processed successfully after multiple retries should be moved to a DLQ. This prevents them from blocking the main processing queue and allows for manual inspection, debugging, and potential reprocessing without losing data. DLQs are crucial for capturing and managing transient or permanent processing failures.
Ordering Guarantees: When Sequence Matters
In certain scenarios, the order in which data is processed by the two APIs is critical. For instance, an "update user profile" message must be processed after an "create user" message. If the order is not maintained, API B might receive an update for a user that API A hasn't yet created, leading to errors or data inconsistencies. Ensuring strict message ordering in a distributed, asynchronous environment is challenging. It often requires partitioning messages by a key (e.g., user ID) to ensure all messages related to a single entity are processed sequentially within a specific consumer group, or implementing custom sequencing logic within the consuming services themselves. If strict ordering is not required, the system can leverage parallel processing for higher throughput, but this decision must be driven by business requirements.
Performance and Latency: The Unseen Drag
The performance characteristics of the two target APIs can vary significantly. One might be an internal, low-latency microservice, while the other could be a high-latency third-party API. If the asynchronous sending mechanism waits for both responses (which negates some async benefits) or if failures in one API cascade, the overall system performance can suffer. This calls for careful resource isolation (e.g., separate thread pools, separate message queues) and intelligent timeout management to prevent a single slow API from degrading the entire data flow. The goal is to maximize throughput and minimize latency for the overall operation, even if individual components exhibit different performance profiles.
Monitoring and Observability: Illuminating the Black Box
In an asynchronous, distributed system, tracing the flow of data and identifying failures becomes substantially more complex. Without robust monitoring and observability, diagnosing issues related to dual API sending can be a nightmare. Key requirements include:
- End-to-End Tracing: Tools like OpenTelemetry or Zipkin allow for correlation of requests across multiple services and message queues, providing a complete view of how data flows from initiation to its final destinations in both APIs.
- Comprehensive Logging: Detailed logs at each stage of the data flow, including message production, consumption, and API invocation, are indispensable for debugging.
- Metrics and Alerts: Collecting metrics such as success rates, latency, error rates, and queue depths for each API call provides crucial insights into system health. Proactive alerts based on these metrics enable rapid detection and response to issues.
Security Considerations: Two Gates, Two Keys
When interacting with two distinct APIs, each may have its own authentication and authorization requirements. This could involve different API keys, OAuth tokens, or even entirely different security protocols. The system responsible for sending the data must securely manage and apply the correct credentials for each API call, ensuring that data is transmitted over secure channels (e.g., HTTPS/TLS) and that unauthorized access is prevented. Centralized credential management and secure secret storage become critical for maintaining the overall security posture.
Addressing these challenges requires a combination of architectural patterns, diligent implementation, and robust operational practices. The subsequent sections will explore specific patterns and strategies that can be employed to overcome these hurdles and achieve highly optimized asynchronous data sending to dual API endpoints.
Architecting for Resilience: Patterns for Asynchronous Dual API Sending
The complexity inherent in sending data asynchronously to two distinct APIs necessitates the adoption of proven architectural patterns. These patterns provide structured approaches to managing concurrency, ensuring data integrity, and building resilient systems that can gracefully handle failures. Each pattern offers a unique set of trade-offs, and the optimal choice often depends on specific business requirements, consistency needs, and existing infrastructure.
The Producer-Consumer Pattern with Message Queues
This is arguably the most prevalent and foundational pattern for asynchronous communication, and it serves as an excellent basis for dual API sending.
How it Works: 1. Producer: The initiating service, upon receiving or generating data, publishes a message (representing the data to be sent) to a dedicated message queue (e.g., RabbitMQ, Kafka, SQS). The producer does not wait for the message to be processed or for API responses; it simply enqueues the message and continues its work. 2. Message Queue: The queue acts as a buffer, storing messages until consumers are ready to process them. It provides decoupling between the producer and consumers, ensuring that spikes in message production don't overwhelm downstream services and that messages are not lost if consumers are temporarily unavailable. 3. Consumers: One or more consumer services continuously poll or subscribe to the message queue. Upon retrieving a message, a consumer processes it by making calls to the target APIs.
Variations for Dual API Sending: * Single Consumer, Dual API Calls: A single consumer application reads messages from the queue. For each message, it attempts to send the data to API A and then to API B. This approach centralizes the logic for dual API interaction, making it easier to manage atomicity (e.g., using a Saga-like pattern within the consumer) and retries. However, if one API is significantly slower, it can block the processing of other messages for that consumer instance. * Two Separate Consumers, Each for One API: The producer publishes a message to a queue. This message is then picked up by two different consumer services (or two separate instances of the same consumer logic). Consumer 1 is responsible for sending data to API A, and Consumer 2 is responsible for sending data to API B. This provides maximum decoupling and allows independent scaling and error handling for each API. If API A's consumer fails, API B's consumer can continue processing. However, ensuring consistency and atomicity across these two independent consumers requires additional mechanisms, often by leveraging shared state or more advanced event correlation. * Fan-out Pattern: The producer publishes a single message to a message broker (like RabbitMQ or Kafka). The message broker then "fans out" this message to multiple queues, where each queue is dedicated to a specific API consumer. This ensures that each API consumer receives a copy of the original message independently.
Benefits: * Decoupling: Producer is completely unaware of the consumers and their processing logic. * Buffering: Message queues can absorb bursts of traffic, preventing downstream systems from being overwhelmed. * Reliability: Queues persist messages, ensuring no data loss even if consumers crash. Built-in retry mechanisms and DLQs enhance fault tolerance. * Scalability: Consumers can be scaled independently based on the load of each API.
Considerations: * Requires a message queue infrastructure, which adds operational overhead. * Ensuring consistency across two separate consumers requires careful design (e.g., tracking the status of both API calls in a persistent store).
Event-Driven Architecture
Building upon the principles of message queues, event-driven architecture (EDA) takes decoupling a step further by focusing on the propagation of domain events.
How it Works: 1. Event Publisher: When a significant event occurs within a service (e.g., OrderCreated, UserProfileUpdated), the service publishes this event to an event bus or message broker. The event typically contains the minimal necessary information about what happened. 2. Event Subscribers: Other services that are interested in specific events subscribe to the event bus. When an event they are interested in is published, they receive it and react accordingly. In our dual API scenario, one subscriber might react to OrderCreated by calling the Inventory API, and another subscriber might react to the same OrderCreated event by calling the Logistics API.
Benefits: * High Decoupling: Services are loosely coupled; they only need to know about the events they publish or consume, not the specific services that react to them. * Scalability: New functionalities (new API calls) can be added by simply creating new subscribers without modifying existing services. * Flexibility: Enables complex, reactive workflows.
Considerations: * Debugging can be more challenging due to the highly distributed nature. * Ensuring eventual consistency across services requires careful event design and idempotent consumers. * Managing schema evolution of events requires a robust strategy.
Saga Pattern
The Saga pattern is specifically designed to manage distributed transactions and maintain data consistency across multiple services when a traditional 2PC is not feasible or desired. It is particularly relevant when ensuring atomicity across two independent API calls.
How it Works: A Saga is a sequence of local transactions. Each local transaction performs an action within a single service and then emits an event that triggers the next local transaction in the Saga. If a local transaction fails, the Saga coordinates compensating transactions to undo the effects of previous successful local transactions.
Two Main Approaches: 1. Choreography-based Saga: Each service produces and listens to events, making decisions and executing its own local transactions. It's decentralized and highly decoupled. For dual API sending, the initial service sends data to API A. Upon success, API A might emit an event, which then triggers a service to send data to API B. If API B fails, it emits a compensation event, triggering a service to undo API A's action. 2. Orchestration-based Saga: A central "Saga Orchestrator" service coordinates all steps of the Saga. It sends commands to participant services, waits for their responses (events), and decides the next step or initiates compensating transactions if a failure occurs. This centralizes the flow logic. In our case, the orchestrator would initiate calls to API A and API B (perhaps via message queues or directly through an API Gateway). If API B fails, the orchestrator sends a command to undo API A's action.
Benefits: * Ensures Eventual Consistency: Guarantees that the overall distributed transaction eventually reaches a consistent state. * High Availability: Avoids long-running, blocking transactions, improving system availability. * Scalability: Can be implemented using asynchronous messaging, allowing for high throughput.
Considerations: * Increased complexity in design and implementation due to compensating transactions. * Debugging can be difficult, especially for choreography-based Sagas. * Requires careful management of transaction states.
Command Pattern with a Centralized Dispatcher
This pattern introduces a dedicated service or component that acts as an intermediary for all outgoing commands (requests) to external APIs.
How it Works: 1. Originating Service: Generates a command (e.g., SendOrderToLogisticsAndCRMCommand) that encapsulates the data and the intention to send it to two APIs. 2. Centralized Dispatcher: This service receives the command. It then breaks down the single command into two distinct commands, one for API A and one for API B, potentially transforming the data as needed for each. It then dispatches these individual commands to a worker pool, message queue, or directly to an API gateway for execution. 3. Workers/Consumers: Execute the specific API calls.
Benefits: * Centralized Control: All logic for sending to multiple APIs is in one place, making it easier to apply cross-cutting concerns like logging, security, and throttling. * Abstraction: Originating services don't need to know about the specifics of sending to two APIs. * Flexibility: Easily adaptable to new APIs or changes in existing API requirements.
Considerations: * The dispatcher can become a single point of contention or failure if not designed for high availability and scalability. * Adds an extra hop in the communication chain.
The Indispensable Role of an API Gateway
In the context of optimizing asynchronous data sending to two APIs, an API gateway emerges not just as a beneficial component, but often as an indispensable one. It acts as a single entry point for all client requests, serving as a powerful intermediary that can abstract backend complexities, enhance security, improve performance, and centralize management for an organization's entire API ecosystem. For dual API interactions, its capabilities extend far beyond simple routing, providing a critical layer of intelligence and resilience.
What is an API Gateway?
At its core, an API gateway is a management layer that sits between clients and a collection of backend services. It acts as a reverse proxy, receiving all API requests, applying various policies, and routing them to the appropriate backend service. In a microservices architecture, where an application might comprise dozens or even hundreds of services, a gateway consolidates these disparate endpoints into a unified, coherent API for external consumers. This centralization is key to managing the complexities of modern distributed systems.
How an API Gateway Facilitates Dual API Sending
The features of an API gateway are particularly well-suited to address many of the challenges associated with asynchronously sending data to two distinct APIs:
- Request Aggregation and Transformation: An API gateway can take a single incoming request from a client, dissect its payload, and then transform and aggregate it into multiple, distinct requests tailored for different upstream APIs. For instance, a client might send a single JSON object containing both user profile data and notification preferences. The gateway can parse this, extract user profile data for API A (User Service) and notification preferences for API B (Notification Service), and then dispatch these two separate requests. This capability significantly simplifies the client-side logic, as clients interact with a single, simplified API endpoint without needing to know about the underlying dual API calls.
- Intelligent Routing: Beyond simple request forwarding, an API gateway provides sophisticated routing capabilities. It can route requests based on various criteria, including the request path, HTTP headers, query parameters, and even elements within the request body. In a dual API scenario, the gateway can be configured to, upon receiving a specific type of request (e.g.,
/api/order-creation), intelligently route a part of the payload to one API and another part to a second API, possibly in parallel or sequentially. This allows for dynamic and condition-based dispatching of data to the correct destinations. - Centralized Security Enforcement: Managing authentication and authorization for two separate APIs, each potentially with different security models, can be burdensome. An API gateway centralizes these crucial security concerns. It can handle client authentication (e.g., API keys, OAuth tokens, JWT validation) at the edge, before requests even reach the backend services. It then injects appropriate authorization credentials (e.g., internal service-to-service tokens) into the requests forwarded to API A and API B. This not only simplifies security for backend services but also enhances the overall security posture by providing a single point of control and enforcement for policies like rate limiting, IP whitelisting, and DDoS protection.
- Resilience and Fault Tolerance: An API gateway significantly enhances the resilience of the dual API sending process. It can implement critical resilience patterns like:
- Circuit Breakers: To prevent cascading failures when one of the backend APIs becomes unhealthy. If API A starts consistently failing, the gateway can "trip" its circuit for API A, immediately returning an error or redirecting to a fallback, thus protecting API A from further load and preventing API B's operation from being stalled by waiting for A.
- Retries and Timeouts: The gateway can be configured with sophisticated retry policies (including exponential backoff) for calls to upstream APIs. It can also enforce strict timeouts, preventing client requests from hanging indefinitely if a backend API is slow or unresponsive. These can be configured independently for each target API.
- Load Balancing: While primarily for distributing traffic across multiple instances of the same service, the gateway can also indirectly facilitate load balancing for dual API scenarios by intelligently routing portions of the data to available instances of distinct services, maximizing throughput.
- Observability and Monitoring: A major benefit of an API gateway is its ability to centralize logging, monitoring, and metrics collection. Every request and response that passes through the gateway can be logged, providing a comprehensive audit trail. This is invaluable for debugging and understanding the flow of data to both API A and API B. The gateway can also emit metrics on request volume, latency, and error rates for each upstream API, offering a holistic view of the system's health and performance at a single glance. This end-to-end visibility is critical for diagnosing issues in asynchronous dual API operations.
- Policy Enforcement and Cross-Cutting Concerns: Beyond security and resilience, an API gateway is an ideal location to enforce other cross-cutting concerns. This might include caching responses (if applicable to one of the APIs), throttling requests to protect backend services, adding custom headers, or even performing data validation before forwarding requests. Centralizing these policies at the gateway layer keeps backend services lean and focused on their core business logic.
- API Versioning and Lifecycle Management: As APIs evolve, managing different versions becomes a challenge. An API gateway simplifies API versioning by routing requests based on version identifiers (e.g.,
api/v1/usersvs.api/v2/users). For dual API sending, this means the gateway can consistently expose a unified interface to clients, even if the underlying API A and API B are undergoing independent version changes. The gateway also plays a critical role in the entire API lifecycle, from publication to deprecation.
For organizations looking to streamline their API management, especially when dealing with complex scenarios like sending data to multiple backend services, an advanced API gateway becomes a critical component. Platforms like ApiPark offer comprehensive solutions. As an open-source AI gateway and API management platform, APIPark provides features like end-to-end API lifecycle management, centralized traffic forwarding, load balancing, and detailed API call logging. Its capabilities to manage the entire API lifecycle, regulate API management processes, and handle traffic forwarding with high performance are invaluable when orchestrating asynchronous data flows to multiple disparate APIs, ensuring reliability and performance while simplifying the operational overhead. While APIPark's primary focus includes integrating 100+ AI models and prompt encapsulation into REST APIs, its underlying robust API management and gateway functionalities are universally applicable to any REST service. This means that even if you're not dealing with AI, APIPark's ability to unify API formats, manage access permissions, and provide detailed call logging and powerful data analysis can significantly enhance the efficiency and security of your dual API sending strategies. Its impressive performance, rivaling Nginx with over 20,000 TPS on modest hardware, further underscores its suitability for high-throughput asynchronous operations. The detailed API call logging and powerful data analysis features are particularly beneficial for troubleshooting and optimizing complex asynchronous interactions, providing deep insights into long-term trends and performance changes, enabling preventive maintenance before issues occur.
Comparison of Architectural Patterns for Dual API Sending
| Feature/Pattern | Producer-Consumer (Single Consumer) | Producer-Consumer (Two Consumers) | Event-Driven Architecture | Saga Pattern (Orchestration) | API Gateway with Transformation |
|---|---|---|---|---|---|
| Complexity | Moderate | Moderate-High | High | High | Low-Moderate (Client-side) |
| Decoupling | High (Producer from Consumer) | Very High | Extremely High | Moderate (Orchestrator from services) | High (Client from Backends) |
| Consistency Guarantee | Requires consumer logic | Requires external coordination | Eventual consistency | Eventual consistency (compensating transactions) | Passthrough/Depends on Backend Logic |
| Error Handling Centralized? | Yes (within consumer) | No (distributed) | No (distributed) | Yes (within orchestrator) | Yes (at Gateway level) |
| Scalability | Good (consumer autoscaling) | Excellent (independent scaling) | Excellent | Good (orchestrator scaling) | Excellent (gateway scaling) |
| Observability | Consumer logs | Distributed logs (harder to trace) | Distributed logs (complex) | Orchestrator logs + distributed tracing | Centralized Gateway logs & metrics |
| Idempotency Support | Requires consumer logic | Requires consumer logic | Requires subscriber logic | Requires service logic | Can enforce at gateway or pass through |
| Latency Impact | Minimal (async nature) | Minimal | Minimal | Minimal | Minimal (async nature of gateway) |
| Key Advantage | Simplicity, clear flow | Max decoupling, independent failure | Highly reactive, flexible | Strong consistency across services | Centralized control, security, resilience, abstraction |
| Key Disadvantage | Single point of failure for logic | Requires external consistency mgmt | Complex to manage | Complex to design & debug | Can become bottleneck if not scaled |
This table illustrates how different architectural patterns address the challenges of dual API sending. The API gateway often complements these patterns by providing the underlying infrastructure for resilience, security, and unified management, making the overall solution more robust and easier to operate. For instance, an API gateway can sit in front of the consumers in a Producer-Consumer pattern, adding a layer of security, rate limiting, and monitoring before requests even hit the consumer services. Or, it can serve as the external entry point for an orchestrator in a Saga pattern, enforcing policies before the orchestrator starts its work.
APIPark is a high-performance AI gateway that allows you to securely access the most comprehensive LLM APIs globally on the APIPark platform, including OpenAI, Anthropic, Mistral, Llama2, Google Gemini, and more.Try APIPark now! 👇👇👇
Fortifying Operations: Implementation Strategies and Best Practices
Beyond choosing the right architectural pattern, the success of optimizing asynchronous data sending to two APIs hinges on meticulous implementation of various strategies that bolster resilience, ensure data integrity, and provide critical observability. These best practices are not optional; they are fundamental to building systems that can withstand the rigors of production environments.
Smart Retries and Exponential Backoff with Jitter
Retries are essential for handling transient network issues, temporary service unavailability, or intermittent backend errors. However, naive retry logic can exacerbate problems, leading to a "thundering herd" where multiple failed clients simultaneously retry, overwhelming the struggling service further.
- Exponential Backoff: The cornerstone of smart retries. Instead of retrying immediately, the client waits for an increasing amount of time between retry attempts (e.g., 1 second, then 2 seconds, then 4 seconds, etc.). This gives the downstream API a chance to recover.
- Jitter: Adding a random component to the exponential backoff (e.g., a random value between 0 and 50% of the calculated backoff time) prevents multiple clients from retrying at precisely the same interval. This smooths out the load on the recovering service.
- Maximum Retries and Time Limits: Implement a sensible cap on the number of retries or a total time limit for the retry process. Beyond these limits, the operation should be considered failed, and the message moved to a Dead Letter Queue for manual intervention or alternative processing. This prevents endless retries from consuming resources.
- Differentiated Policies: As discussed, allow for different retry policies for each of the two target APIs, reflecting their distinct reliability profiles and performance characteristics.
Circuit Breaker Pattern: Preventing Cascading Failures
The Circuit Breaker pattern is a vital defense mechanism against cascading failures in distributed systems. When one of your target APIs becomes unresponsive or starts returning a high rate of errors, continuing to send requests to it is futile and only worsens the situation.
- Operation: A circuit breaker wraps a protected function call (e.g., an API invocation). It monitors the number of failures. If the failure rate exceeds a threshold within a specified time window, the circuit "trips" open.
- Open State: While open, all subsequent calls to the protected function fail immediately, either by returning an error to the caller or by invoking a fallback mechanism, without attempting to reach the struggling API. This gives the failing API time to recover and prevents the calling service from consuming resources on futile requests.
- Half-Open State: After a configured timeout, the circuit transitions to a "half-open" state. A limited number of test requests are allowed through. If these requests succeed, the circuit closes, and normal operations resume. If they fail, the circuit returns to the open state for another period.
- Closed State: Normal operation. Requests pass through.
Implementing circuit breakers for calls to both API A and API B, potentially as part of an API gateway or within your consumer services, ensures that an outage in one API doesn't destabilize the entire system or prevent data from being sent to the healthy API.
Bulkheading: Isolating Failure Domains
Inspired by the compartments in a ship, bulkheading involves isolating components of your system to prevent a failure in one area from sinking the entire application. For dual API sending, this means:
- Separate Thread Pools: Use dedicated thread pools for calls to API A and API B. If API A becomes slow or unresponsive, only the thread pool for API A will be exhausted, leaving the thread pool for API B free to process requests.
- Separate Message Queues: If using the Producer-Consumer pattern, consider using separate queues or separate partitions within a queue for messages destined for API A versus API B, especially if their processing characteristics are wildly different. This ensures that a backlog of messages for one API doesn't impede the processing of messages for the other.
- Resource Limits: Implement resource limits (CPU, memory) for different components or services to ensure that a runaway process interacting with one API doesn't starve resources needed for the other.
Timeouts: Setting Clear Expectations
Explicitly defining and enforcing timeouts for all external API calls is crucial. Without timeouts, a slow or unresponsive API can cause threads to hang indefinitely, consuming resources and eventually leading to system instability.
- Connection Timeout: How long to wait to establish a connection.
- Read Timeout: How long to wait for data to be received after a connection is established.
- Overall Transaction Timeout: Beyond individual API call timeouts, consider an overall timeout for the entire dual API sending operation. If the combined process of sending to both APIs (including retries) exceeds this limit, the operation should be abandoned, and the message handled as a failure.
- Reasonable Values: Set timeouts aggressively but reasonably, based on the expected performance of each API. Too short, and you'll get spurious errors; too long, and you risk resource exhaustion.
Idempotency Keys: A Cornerstone of Reliability
As discussed, idempotency is critical for systems that involve retries. When sending data to API A and API B, ensure that your system generates and uses unique idempotency keys for each operation.
- Generation: These keys should be unique identifiers associated with the logical operation being performed (e.g., an order ID, a request UUID).
- Propagation: The key should be included in the request headers or body for both API calls.
- API Implementation: Both API A and API B must be designed to store and check these idempotency keys. If a request with an already processed key is received, the API should simply return the previous successful response without re-executing the operation. This is especially important for financial transactions or state-changing operations.
Transactional Outbox Pattern: Bridging Databases and Message Queues
When a service needs to both update its internal database and publish a message to a queue (which in turn might trigger API calls), ensuring atomicity between these two actions is vital. The Transactional Outbox pattern addresses this "dual write" problem.
- Mechanism: Instead of directly publishing a message to a queue, the service writes a record of the outgoing message into a special "outbox" table within the same database transaction as the state change.
- Atomic Operation: If the database transaction fails, both the state change and the outbox entry are rolled back. If it succeeds, both are committed. This ensures that the message is only published if the database state change is successful.
- Relay Service: A separate "relay service" or "outbox publisher" periodically polls the outbox table for new, unpublished messages. It then publishes these messages to the actual message queue and marks them as published.
- Benefits: Guarantees that the message is eventually published if and only if the database transaction succeeds, providing strong atomicity and preventing data inconsistencies.
Monitoring and Alerting: Seeing in the Dark
In asynchronous, distributed systems, "what you can't measure, you can't improve." Robust monitoring and alerting are non-negotiable.
- Key Metrics: Collect metrics for each API call:
- Success Rate: Percentage of successful calls.
- Error Rate: Percentage of failed calls (broken down by error type).
- Latency: Average, p95, p99 latency for responses.
- Throughput: Number of requests per second.
- Queue Depth: For message queues, monitor the number of messages awaiting processing.
- Distributed Tracing: Implement distributed tracing (e.g., using OpenTelemetry, Jaeger, Zipkin) to visualize the entire request flow across your services, message queues, and API calls. This allows you to pinpoint bottlenecks and identify the root cause of failures quickly.
- Structured Logging: Ensure all services emit structured logs (e.g., JSON format) with correlation IDs. This makes it easier to aggregate, search, and analyze logs across different components.
- Proactive Alerting: Configure alerts based on predefined thresholds for critical metrics (e.g., high error rate for API A, elevated latency for API B, rapidly growing queue depth). Integrate alerts with notification systems (email, Slack, PagerDuty) to ensure rapid response to anomalies.
- Dashboards: Create intuitive dashboards that provide real-time visibility into the health and performance of your dual API sending processes.
Testing Strategies: Building Confidence
Thorough testing is paramount for complex asynchronous interactions.
- Unit Tests: Test individual components (e.g., the consumer logic, retry mechanisms) in isolation.
- Integration Tests: Verify the interaction between your service and each individual API, and then the combined interaction with both APIs. Mock external dependencies where necessary, but also perform tests against staging environments of the actual APIs.
- End-to-End Tests: Simulate complete business workflows, from the initial data generation to its final processing by both API A and API B, verifying data consistency and correctness.
- Chaos Engineering: Deliberately inject failures (e.g., introduce network latency, make one API unavailable, increase error rates) to test the resilience mechanisms (retries, circuit breakers) in a controlled environment.
- Performance Testing: Load test your system to understand its behavior under high concurrency, measure throughput, latency, and resource utilization, especially when interacting with two potentially varying-performance APIs.
Data Consistency Models: Eventual vs. Strong
When dealing with multiple APIs, achieving strong consistency (all systems always agree on the state) is often impractical or prohibitively expensive. Eventual consistency is a more common and scalable approach for distributed systems.
- Eventual Consistency: Guarantees that if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value. This is often acceptable for many business scenarios (e.g., an order eventually shows up in both inventory and CRM).
- Strategies for Reconciliation: If eventual consistency is chosen, design mechanisms to detect and resolve inconsistencies that might arise during temporary divergence. This could involve periodic reconciliation jobs that compare data across systems and correct discrepancies.
- Business Requirements: The choice between strong and eventual consistency must always be driven by the specific business requirements. For financial transactions, stronger consistency guarantees might be mandated, requiring more complex patterns like Sagas with robust compensation. For analytical data, eventual consistency is often perfectly adequate.
By diligently applying these implementation strategies and best practices, organizations can construct highly optimized and resilient systems for asynchronous data sending to two APIs, ensuring reliability, maintainability, and operational efficiency in even the most demanding distributed environments.
Real-World Applications: Use Cases and Examples
To truly appreciate the importance of optimizing asynchronous data sending to two APIs, it's beneficial to explore common real-world scenarios where this pattern is critical. These examples highlight the diverse challenges and the necessity of robust solutions.
1. E-commerce Order Processing
Scenario: A customer places an order on an e-commerce website. This single action triggers multiple backend operations.
- API A (Internal Inventory API): Needs to deduct the ordered items from stock. This is a critical operation for preventing overselling.
- API B (Third-Party Logistics/Fulfillment API): Needs to receive the order details (shipping address, items, quantities) to initiate the shipping process.
- API C (Internal CRM/Customer History API): Needs to record the order against the customer's profile for future analytics, marketing, and support. (While the article focuses on two, a third is often involved, emphasizing the pattern's generality.)
Challenges: * Atomicity: Ideally, inventory should only be deducted if the order can be fulfilled by logistics. If logistics fails, inventory deduction might need to be rolled back or accounted for. * Timing: Inventory deduction should happen quickly to reserve stock. Logistics might be eventually consistent. * Retries: If the Logistics API is temporarily down, the order details must be retried reliably without causing duplicate inventory deductions.
Solution Approach: A message queue (e.g., Kafka) is a common choice. The "Order Created" event is published to a topic. * A consumer service subscribes to this topic, processes the message, and first calls the Inventory API. * Upon successful inventory deduction (or even in parallel with a "tentative deduction"), another consumer (or the same one) calls the Logistics API. * If either API call fails, robust retry logic with exponential backoff and circuit breakers is crucial. * Idempotency keys generated from the order_id are passed to both APIs to prevent duplicate processing. * The CRM update can happen eventually, perhaps triggered by another event after the order is confirmed and shipped.
2. User Registration and Onboarding
Scenario: A new user signs up for a service.
- API A (User Profile Management API): Stores the user's core details (email, password hash, personal info). This is often the most critical initial step.
- API B (Notification Service API): Sends a welcome email or a two-factor authentication (2FA) setup prompt to the new user.
Challenges: * Consistency: The welcome email should ideally only be sent if the user profile is successfully created. * Latency: User profile creation must be quick. Email sending can tolerate slightly higher latency. * Failure Handling: If the email API fails, the user profile should still be created successfully. The email send should be retried in the background.
Solution Approach: An event-driven architecture is highly suitable here. * Upon successful user profile storage in the User Profile Management API, a UserCreated event is published to an event bus. * A separate "Notification Listener" service subscribes to UserCreated events. When it receives one, it calls the Notification Service API to send the welcome email. * The Notification Listener includes its own retry logic and potentially a DLQ for persistent email sending failures. * The user is informed immediately after their profile is created, even if the welcome email is still pending or retrying.
3. IoT Data Ingestion and Processing
Scenario: A fleet of IoT sensors continuously sends telemetry data. This data needs to be stored for historical analysis and simultaneously processed for real-time insights.
- API A (Time-Series Database API): Stores raw sensor data (temperature, pressure, location) in a specialized database optimized for time-series workloads.
- API B (Real-time Analytics API): Receives the same sensor data to detect anomalies, trigger alerts, or update dashboards in real-time.
Challenges: * High Throughput: IoT devices can generate massive volumes of data. * Performance: Both storage and real-time analytics need to be highly performant. * Ordering (Optional): For certain analyses, preserving the exact order of sensor readings might be critical, but for many, approximate order with high throughput is preferred.
Solution Approach: Apache Kafka is an excellent choice for its high throughput, durability, and stream processing capabilities. * IoT gateways or edge devices publish sensor data streams directly to Kafka topics. * A dedicated "Storage Consumer" group reads from the Kafka topic and writes data efficiently to the Time-Series Database API. * A separate "Analytics Consumer" group reads from the same Kafka topic (allowing for multiple consumers to process the same stream independently) and feeds the data to the Real-time Analytics API for immediate processing. * Kafka's consumer groups ensure that each message is processed by at least one consumer in each group, allowing independent scaling for storage and analytics. Bulk processing and batching can be applied by consumers to optimize writes to the APIs.
4. Financial Transactions and Fraud Detection
Scenario: A payment gateway processes a credit card transaction.
- API A (Internal Ledger API): Records the transaction in the financial ledger, updating account balances. This is a highly critical, atomic operation.
- API B (Fraud Detection API): Sends transaction details to a real-time fraud detection service to screen for suspicious activities.
Challenges: * Strict Consistency (Ledger): The ledger update must be absolutely atomic and consistent. * Real-time Fraud Detection: Fraud detection needs to happen almost instantly to prevent financial loss. * Error Handling: If the fraud detection API is slow, the ledger update should not be blocked, but the transaction might need to be flagged for post-transaction review.
Solution Approach: This scenario often requires a hybrid approach or a robust Saga pattern. * The initial payment processing service attempts to debit the customer's account. This is a local transaction. * Transactional Outbox Pattern: The service updates its internal database with the transaction details and simultaneously writes an "outgoing message" record to an outbox table within the same database transaction. * A relay service then picks up the message from the outbox and publishes it to a message queue. * Consumer 1 (Ledger Service): Reads the message and calls the Ledger API. This service must ensure idempotency and handle its own robust error handling for the critical ledger update. * Consumer 2 (Fraud Detection Service): Reads the same message and calls the Fraud Detection API. This call might be time-sensitive, potentially with a shorter timeout. If it fails, the transaction might proceed but be marked for manual review, demonstrating how different error handling strategies apply. * Saga Orchestrator (Optional): For higher levels of atomicity across both, an orchestrator could coordinate: 1. Debit account, 2. Notify Ledger API, 3. Notify Fraud Detection API. If fraud detection flags the transaction, a compensation step would reverse the debit. This ensures a consistent view across systems.
These examples illustrate that while the core challenge is sending data to two APIs, the specific implementation details and the choice of patterns vary significantly based on consistency requirements, performance expectations, and tolerance for failure. In each case, leveraging an API gateway (like APIPark) would greatly simplify the management, security, and observability aspects of these external API interactions, providing a robust and scalable foundation for the entire system.
Glimpses into the Future: Advanced Topics and Considerations
As distributed systems continue to evolve, new technologies and patterns emerge that can further optimize asynchronous data sending to multiple APIs. While the core principles remain constant, these advanced topics offer avenues for greater efficiency, resilience, and operational simplicity.
Serverless Functions for Event Processing
The rise of serverless computing (e.g., AWS Lambda, Azure Functions, Google Cloud Functions) offers a compelling model for event-driven asynchronous processing.
- Mechanism: Instead of persistent consumer services, serverless functions can be triggered directly by messages arriving in a queue (e.g., SQS, Kafka, Pub/Sub) or by events published to an event bus.
- Dual API Sending: A single serverless function can be invoked per message. Within this function, you can implement the logic to call both API A and API B in parallel or sequentially.
- Benefits:
- Reduced Operational Overhead: No servers to provision, patch, or scale manually. The cloud provider manages infrastructure.
- Automatic Scaling: Functions scale automatically with load, handling bursts of messages effortlessly.
- Cost-Efficiency: You only pay for the compute time consumed, making it highly cost-effective for intermittent or variable workloads.
- Considerations:
- Cold Starts: Initial invocations of a function after inactivity can incur a slight latency penalty.
- Statelessness: Functions are typically stateless, requiring external storage for any persistent state (e.g., idempotency tracking).
- Vendor Lock-in: While open-source solutions exist, extensive use of cloud-specific serverless offerings can lead to vendor lock-in.
Service Mesh: Empowering Inter-Service Communication
In complex microservices architectures, a service mesh (e.g., Istio, Linkerd) provides a dedicated infrastructure layer for handling inter-service communication. It acts as a proxy (sidecar) for each service instance, intercepting all inbound and outbound traffic.
- Relevance to Dual APIs: While primarily focused on communication between services within the mesh, a service mesh can offload many resilience patterns (retries, circuit breakers, timeouts) from application code into the infrastructure layer. If your "sending service" is part of a mesh and calls to external APIs are routed through the mesh's egress gateway, the mesh can apply these policies automatically.
- Benefits:
- Observability: Provides deep insights into network traffic, latency, and errors for all service-to-service communication.
- Traffic Management: Enables advanced routing, load balancing, and traffic shifting capabilities.
- Security: Enforces mTLS (mutual TLS) between services and applies authorization policies.
- Considerations:
- Complexity: A service mesh adds a significant layer of operational complexity and requires expertise to deploy and manage.
- Overhead: The sidecar proxy introduces some resource and latency overhead.
- External vs. Internal: While a service mesh excels at internal communication, its direct impact on external API calls might require integration with an API gateway for a complete edge-to-backend solution.
GraphQL Gateway: Data Aggregation and Flexible Clients
While not directly a pattern for sending data to two distinct backend APIs in the traditional sense, a GraphQL gateway can play a role in optimizing data consumption from multiple sources, which can be an inverse of the problem.
- Mechanism: A GraphQL gateway provides a single endpoint where clients can query for data using a flexible GraphQL query language. The gateway then federates these queries, fetching data from multiple underlying REST APIs or microservices, aggregating the results, and returning a unified response.
- Indirect Relevance: If the data you are sending to API A and API B is later consumed by clients, a GraphQL gateway could simplify how clients then retrieve the results or the updated state from these various backend services, abstracting the multi-API complexity.
- Considerations:
- Primarily for data retrieval (reads), less directly for data mutations (writes) to multiple disparate APIs with differing schemas.
- Adds another layer of abstraction and potential complexity.
Data Governance and Compliance
As data flows asynchronously to multiple endpoints, ensuring adherence to data governance policies and regulatory compliance (e.g., GDPR, CCPA, HIPAA) becomes paramount.
- Data Masking/Anonymization: If sensitive data is sent to a less secure API (e.g., for analytics), ensure it is appropriately masked or anonymized before transmission. An API gateway can perform these transformations.
- Data Residency: Verify that data does not leave specific geographic regions if mandated by regulations.
- Audit Trails: Maintain comprehensive, immutable audit trails of all data transmissions, including timestamps, source, destination, and payload details. The detailed logging capabilities of an API gateway like APIPark are invaluable here.
- Access Control: Ensure that only authorized systems and personnel have access to the data in transit and at rest in all target APIs. Independent API and access permissions for each tenant, as offered by APIPark, are crucial for multi-team or multi-departmental scenarios.
These advanced considerations highlight the ongoing evolution of distributed systems and the ever-increasing need for sophisticated solutions to manage complexity, improve resilience, and ensure compliance. By understanding and strategically applying these concepts, architects and developers can future-proof their asynchronous data sending mechanisms to two, or even more, APIs.
Conclusion
Optimizing asynchronous data sending to two APIs is a quintessential challenge in modern distributed systems, embodying the complexities of integration, resilience, and data consistency. From ensuring idempotency and atomicity across disparate endpoints to crafting intelligent retry mechanisms and implementing robust observability, each facet demands meticulous attention. The journey through architectural patterns like the Producer-Consumer, Event-Driven, and Saga patterns reveals a landscape of choices, each offering distinct advantages and trade-offs in terms of coupling, consistency, and operational complexity.
At the heart of any sophisticated solution for managing multiple API interactions lies the API gateway. As a centralized control point, it not only abstracts backend complexities but also acts as an enforcement layer for security, a critical orchestrator for resilience patterns like circuit breakers and timeouts, and a vital hub for comprehensive logging and monitoring. Platforms like ApiPark, with their open-source nature and robust feature set for API management, gateway functionalities, and AI model integration, offer invaluable tools for organizations seeking to streamline and fortify their API ecosystems. Its ability to unify API formats, manage traffic, and provide powerful data analysis significantly simplifies the daunting task of orchestrating asynchronous data flows to multiple APIs, ensuring both high performance and secure, compliant operations.
Ultimately, successful asynchronous dual API sending is not merely about making two HTTP calls. It is about embracing a holistic approach that integrates intelligent architectural design, diligent implementation of resilience patterns, proactive monitoring, and a continuous commitment to testing. As systems become increasingly distributed and interconnected, the ability to reliably and efficiently dispatch data to multiple external destinations will remain a cornerstone of building scalable, robust, and future-proof applications, continuously optimizing efficiency, security, and data optimization for developers, operations personnel, and business managers alike.
Frequently Asked Questions (FAQ)
1. Why is sending data asynchronously to two APIs more complex than to one?
Sending data to two APIs asynchronously introduces complexity primarily due to the independent nature of the two operations. Challenges arise in maintaining data consistency (what if one succeeds and the other fails?), managing different error handling and retry policies for each, ensuring idempotency across multiple targets, dealing with varying latencies, and effectively monitoring the end-to-end process when failures can occur in isolation. Unlike a single API call, you're orchestrating a distributed transaction of sorts, even if it's eventually consistent.
2. What is the role of an API Gateway in optimizing dual API sending?
An API gateway acts as a centralized intermediary that can significantly optimize dual API sending by providing a single entry point for clients. It can aggregate and transform a single client request into multiple requests for backend APIs, enforce centralized security policies (authentication, authorization, rate limiting), implement resilience patterns (circuit breakers, intelligent retries, timeouts) at the edge, and provide comprehensive logging and monitoring for all API traffic. This abstracts complexity from clients and backend services, enhances security, and improves overall system resilience and observability.
3. How does idempotency help in asynchronous dual API operations?
Idempotency is crucial in asynchronous dual API operations, especially when retry mechanisms are in place. Since messages or requests might be re-sent due to network issues or API failures, an idempotent operation guarantees that executing it multiple times with the same input produces the same result as executing it once. For dual API sending, this prevents duplicate data entries, incorrect state changes (e.g., double-deducting inventory), or redundant notifications if one API succeeds and the other fails, leading to a retry of the entire operation. Implementing idempotency usually involves passing a unique idempotency key with each request.
4. When should I use the Saga pattern for sending data to two APIs?
The Saga pattern is particularly useful when you need to maintain data consistency across two (or more) independent services that do not share a common database, and where a traditional distributed transaction (like 2PC) is not feasible or desirable due to its performance and availability overhead. It's ideal for scenarios requiring eventual consistency, where an overarching business process spans multiple API calls, and if any step fails, you need a mechanism to undo (compensate) the previously completed steps to maintain a consistent overall state. Examples include complex e-commerce order fulfillment or financial transaction workflows.
5. What are the key metrics to monitor for optimizing asynchronous data sending to two APIs?
For effective optimization and troubleshooting, you should monitor several key metrics for each API: * Success Rate & Error Rate: Percentage of successful vs. failed API calls to both API A and API B, broken down by error type. * Latency: Average, P95, and P99 latency of API responses from both APIs. * Throughput: The number of requests processed per second by each API. * Queue Depth: If using message queues, monitor the number of messages waiting in the queue to be processed by consumers sending to these APIs. * Resource Utilization: CPU, memory, and network usage of your sending services and any API gateway involved. * Circuit Breaker State: Monitor if any circuit breakers are open or half-open, indicating struggling downstream services. These metrics, combined with distributed tracing and structured logging, provide a comprehensive view of the system's health and performance.
🚀You can securely and efficiently call the OpenAI API on APIPark in just two steps:
Step 1: Deploy the APIPark AI gateway in 5 minutes.
APIPark is developed based on Golang, offering strong product performance and low development and maintenance costs. You can deploy APIPark with a single command line.
curl -sSO https://download.apipark.com/install/quick-start.sh; bash quick-start.sh

In my experience, you can see the successful deployment interface within 5 to 10 minutes. Then, you can log in to APIPark using your account.

Step 2: Call the OpenAI API.

