How to Asynchronously Send Data to Two APIs Efficiently
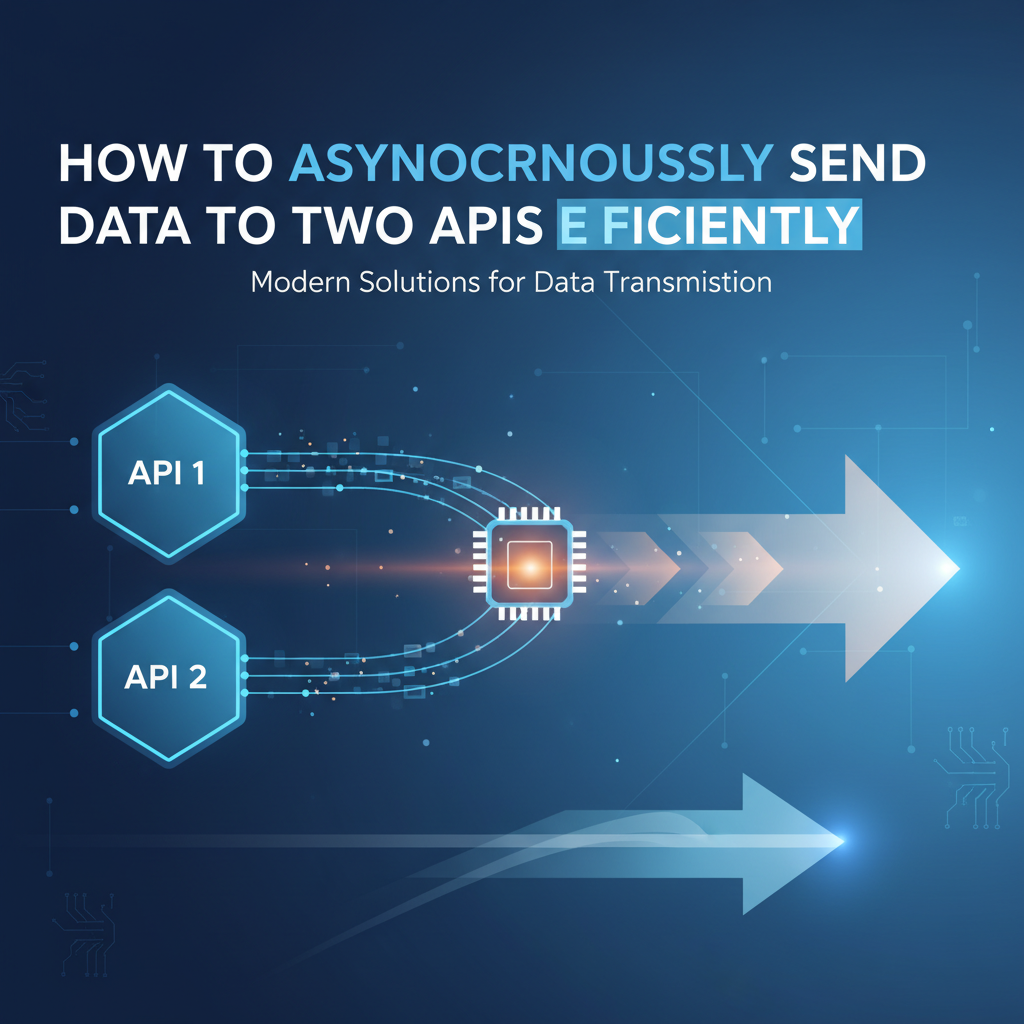


In the intricate landscape of modern software development, applications rarely operate in isolation. They are constantly interacting with external services, databases, and, most frequently, other Application Programming Interfaces (APIs). Whether it's updating user profiles across multiple platforms, processing payments and simultaneously notifying inventory systems, or aggregating data from disparate sources, the need to communicate with multiple APIs is ubiquitous. However, the manner in which these communications are handled profoundly impacts an application's performance, responsiveness, and overall user experience. Sending data to two or more APIs synchronously can introduce significant latency, turning what should be a swift operation into a frustrating waiting game. This is where the power of asynchronous communication truly shines, offering a pathway to dramatically enhance efficiency.
The paradigm shift from synchronous to asynchronous processing is not merely a technical detail; it's a fundamental change in how we conceive of and design interactive systems. When an application makes a synchronous API call, it effectively pauses its own execution, waiting idly for the remote server to process the request and return a response. This blocking behavior, while simple to implement for single operations, becomes a crippling bottleneck when multiple external calls are required. Each subsequent call must wait for the preceding one to complete, leading to a cumulative delay that scales directly with the number of APIs involved and their individual response times. Imagine a user clicking "purchase" on an e-commerce site, only for the application to sequentially contact the payment gateway, then the order fulfillment API, then the inventory management API, and finally the notification API, all while the user stares at a loading spinner. Such an experience is antithetical to modern expectations of speed and fluidity.
Asynchronous operations liberate an application from this sequential dependency. Instead of waiting, the application can initiate an API request and immediately move on to other tasks, including initiating another API request. The responses, when they eventually arrive, are handled separately, often through callbacks, promises, or async/await constructs. This non-blocking nature allows multiple api requests to be "in flight" concurrently, significantly reducing the total time taken for an aggregate operation. For applications that frequently interact with external apis, particularly those requiring data submission to more than one api, mastering asynchronous techniques is not just an optimization; it is a necessity for building scalable, resilient, and high-performance systems. Moreover, as applications evolve and incorporate more microservices and third-party integrations, the complexity of managing these interactions grows exponentially, underscoring the critical role that efficient api communication strategies, often facilitated by an api gateway, play in maintaining system health and developer sanity.
This comprehensive guide delves deep into the mechanisms, strategies, and best practices for asynchronously sending data to two APIs efficiently. We will explore the foundational concepts of asynchronous programming, dissect common challenges, and present practical solutions using various programming paradigms. Furthermore, we will examine the transformative role of an api gateway in simplifying and enhancing these complex multi-api interactions, ultimately empowering developers to build faster, more robust, and more user-friendly applications.
Understanding Asynchronous Operations: The Foundation of Efficiency
To truly appreciate the efficiency gains offered by asynchronous communication, it is crucial to first grasp its core principles and how it fundamentally differs from its synchronous counterpart. Asynchronous operations are a cornerstone of modern software architecture, particularly prevalent in networked applications, user interfaces, and any system that deals with I/O-bound tasks.
Synchronous vs. Asynchronous: A Fundamental Distinction
At its heart, the difference between synchronous and asynchronous operations boils down to whether a task's initiation blocks the execution of subsequent tasks.
Synchronous Operations: When an operation is performed synchronously, the program flow halts at the point of initiation until that specific operation is fully completed and a result is returned. Only then does the program proceed to the next line of code. Think of it like waiting in line at a coffee shop: you place your order, and you stand there, unmoving, until your coffee is ready. You cannot start doing anything else, like checking your phone or reading a newspaper, until you have your coffee in hand. In the context of API calls, this means: * Blocking: The calling thread or process is blocked, idle, until the API responds. * Sequential Execution: If you need to call two APIs, API_A and API_B, API_B cannot even begin to process until API_A has completely finished and returned its result. This creates a waterfall effect, where the total execution time is the sum of the individual API call durations plus any network latency in between. * Resource Inefficiency: While waiting, the blocked thread consumes system resources without performing any productive work. This limits the application's ability to handle multiple concurrent requests or perform other tasks.
Asynchronous Operations: In contrast, an asynchronous operation allows the program to initiate a task and then immediately continue with other operations without waiting for the initiated task to complete. The program essentially says, "Start this task for me, and let me know when it's done. In the meantime, I'll go do something else." Using the coffee shop analogy, an asynchronous approach would be ordering your coffee, receiving a pager, and then going to find a table, perhaps checking emails, or even placing another food order. When the pager vibrates, you go back to pick up your coffee. In the realm of API interactions, this translates to: * Non-Blocking: The calling thread is not blocked. It can initiate an API request and then immediately proceed to the next instruction in its execution flow. * Concurrent Execution: Multiple API calls can be initiated almost simultaneously. While API_A is processing the first request on the remote server, API_B can be receiving and processing its own request. The application itself is not waiting for either. * Resource Efficiency: By not blocking, the thread can be used to process other tasks, handle other incoming requests, or initiate further operations. This significantly improves an application's throughput and responsiveness, making better use of system resources.
Why Asynchronous Operations are Crucial for API Interactions
The very nature of API interactions, which involve network communication over potentially long distances, makes them inherently prone to latency. Even with fast internet connections, network hops, server processing times, and data serialization/deserialization all contribute to delays. When an application needs to interact with multiple apis, these individual delays can quickly accumulate into unacceptable waiting times if processed synchronously.
Consider a scenario where an application needs to send user data to a CRM api and an analytics api after a user signs up. If each api call takes 500ms (a not uncommon round-trip time for external services), a synchronous approach would result in a 1-second delay (500ms + 500ms) before the application can confirm the signup to the user. If there were five such APIs, the delay could easily stretch to 2.5 seconds or more. This kind of cumulative delay can severely degrade the user experience, leading to abandonment or frustration.
Asynchronous operations circumvent this problem entirely. By initiating both the CRM api call and the analytics api call concurrently, the application only has to wait for the longest of the two individual api calls to complete, rather than their sum. In our example, if both take 500ms, the total effective wait time is closer to 500ms (plus a tiny overhead for managing the async operations), not 1 second. This dramatically improves the perceived and actual performance of the application.
Furthermore, asynchronous programming is particularly vital in environments where a single server needs to handle numerous client requests simultaneously. For instance, a web server built with a synchronous model would need to dedicate a separate thread or process to each incoming request, and if that thread then makes a synchronous call to an external api, it remains blocked until the api responds. This quickly depletes thread pools and server resources, leading to degraded performance and inability to scale. An asynchronous server, conversely, can use a few threads or even a single thread with an event loop to manage thousands of concurrent api calls and client connections, switching context efficiently while waiting for I/O operations to complete. This efficiency is critical for modern web services, microservices architectures, and high-traffic applications that demand high throughput and low latency.
The adoption of asynchronous patterns is not just about speed; it's about building more resilient, scalable, and responsive systems that can handle the unpredictable nature of network communication and external service dependencies gracefully. It allows applications to remain interactive, even when backend apis are slow or temporarily unavailable, by managing the waiting periods without freezing the entire application flow.
Challenges of Interacting with Multiple APIs
While the benefits of asynchronous communication are clear, the process of interacting with multiple APIs, especially asynchronously, is not without its complexities. Developers must contend with a myriad of challenges that can impact an application's stability, performance, and data integrity. Addressing these proactively is key to building robust multi-api solutions.
Network Latency and Variability
The most fundamental challenge when dealing with external APIs is network latency. Data has to travel across the internet, traversing numerous routers and switches, before reaching the remote server and then making the return journey. This process introduces delays that are unpredictable and highly variable. Factors such as geographical distance, network congestion, server load at the api provider, and even the quality of the internet connection can all contribute to fluctuating response times.
When sending data to two distinct APIs, even if initiated asynchronously, one api might respond quickly while the other might experience significant delays. This variability complicates the coordination of results, especially if subsequent actions depend on the successful completion of both. Moreover, transient network issues, such as packet loss or temporary outages along the route, can lead to failed requests, requiring sophisticated retry mechanisms. Without careful handling, an application could end up waiting for an excessively long time for a delayed api or prematurely giving up on a request that might have succeeded with a little more patience.
Rate Limits and Throttling
Many public and even private APIs impose rate limits to prevent abuse, ensure fair usage, and protect their infrastructure from being overwhelmed. These limits define how many requests an application can make within a specific timeframe (e.g., 100 requests per minute, 10 requests per second). Exceeding these limits typically results in HTTP 429 Too Many Requests errors, and repeated violations can lead to temporary or even permanent blocking of your application's access.
When making asynchronous calls to multiple APIs, the risk of hitting rate limits increases. It's easy to accidentally flood an api with concurrent requests, especially if each individual api call is fast and the application is designed to initiate many operations in parallel. Developers must implement client-side throttling mechanisms to respect these rate limits. This often involves tracking the number of requests made within a window and pausing further requests if a limit is approached. Furthermore, different APIs often have different rate limits, adding another layer of complexity to the client-side management logic. An api gateway can be instrumental in managing these on a centralized basis, as we will discuss later.
Error Handling and Resilience
Errors are an inevitable part of network communication. An API call can fail for numerous reasons: the remote server might be down, the network connection could drop, the request might be malformed, or the API might return a business logic error. When sending data to two APIs asynchronously, the situation becomes more complex. One api might succeed while the other fails, leading to partial updates or inconsistent states.
Robust error handling involves: * Distinguishing Error Types: Understanding if an error is transient (e.g., network timeout) or permanent (e.g., invalid authentication). * Retry Mechanisms: For transient errors, implementing a retry strategy, often with exponential backoff (waiting longer between successive retries), can improve resilience. However, this must be carefully balanced to avoid hammering a struggling api. * Circuit Breakers: A design pattern that prevents an application from repeatedly trying to access a failing remote service, which can worsen the problem. Instead, it "breaks" the circuit, quickly failing requests to the unhealthy service for a predefined period, allowing the service time to recover. * Fallback Mechanisms: Defining alternative actions or default values if an api call fails, to ensure the application can still provide a graceful user experience or partial functionality. * Idempotency: Designing data submission operations to be idempotent, meaning sending the same request multiple times has the same effect as sending it once. This is crucial for retries, as it prevents duplicate creations or unintended side effects if a request is processed more than once due to network uncertainties.
Managing these error scenarios across multiple concurrent api calls requires careful orchestration to ensure data consistency and application stability.
Data Consistency and State Management
When an application sends data to two separate APIs, there's a significant risk of data inconsistency if one operation succeeds and the other fails. For example, if you're updating a user's subscription status in your billing api and their profile api, and the billing api succeeds but the profile api fails, the user might be charged for a service that their profile doesn't reflect, leading to user dissatisfaction and support tickets.
Achieving eventual consistency is often the goal in such distributed systems, but the path to it can be complex. Strategies include: * Transaction Management: While true distributed transactions across different external APIs are difficult (and often ill-advised) to implement due to their blocking nature and complexity, alternative patterns exist. * Compensating Transactions: If one api call fails after another succeeds, a compensating action might be needed to "undo" the successful operation, bringing the system back to a consistent state. This requires careful design and often involves queues or event logs. * Atomic Operations (where possible): Designing apis to support atomic updates if multiple fields are being modified, or ensuring the sequence of updates minimizes inconsistency windows. * Event-Driven Architectures: For highly critical operations, pushing changes to a message queue after the first api call, and letting a separate worker process handle the second api call, can provide more robust consistency guarantees and easier recovery from failures.
The challenge lies in orchestrating these operations such that the system state remains coherent across all involved services, even in the face of partial failures or network disruptions.
Dependency Management and Orchestration
Sometimes, the data sent to one api might depend on the response received from another api. For instance, you might first need to create a resource in API_A to obtain an ID, and then use that ID to create a related resource in API_B. While this inherently introduces a sequential dependency, the other parts of your application should ideally not be blocked while these two dependent api calls are being processed.
Orchestrating such dependencies within an asynchronous framework requires careful structuring of your code. Promises or async/await patterns are excellent for chaining dependent asynchronous operations while still allowing the main application thread to remain unblocked. However, managing complex dependency graphs, where multiple branches of asynchronous calls might converge or diverge, can quickly become unwieldy without proper architectural patterns. Moreover, if your application needs to combine data from various apis before sending it elsewhere, the aggregation and transformation logic adds further layers of complexity, making the case for a robust api gateway even stronger.
By diligently addressing these challenges, developers can unlock the full potential of asynchronous api communication, building applications that are not only faster but also more resilient, scalable, and manageable.
Core Concepts for Asynchronous API Calls
Implementing efficient asynchronous API calls hinges on a solid understanding of several fundamental concepts and programming patterns. These concepts provide the bedrock upon which modern non-blocking I/O operations are built across various programming languages and environments.
Concurrency vs. Parallelism: Demystifying the Distinction
While often used interchangeably, concurrency and parallelism are distinct concepts that describe how tasks are executed. Understanding their difference is vital for designing efficient asynchronous systems.
- Concurrency: Deals with managing multiple tasks at the same time through interleaving. It gives the appearance of multiple tasks running simultaneously, even if there's only one CPU core. A single CPU core can rapidly switch between different tasks, executing a small part of one, then a small part of another, and so on. For I/O-bound tasks (like waiting for an API response), the CPU often sits idle while waiting. Concurrency allows the CPU to switch to another task during this idle time, maximizing its utilization. Think of a chef juggling multiple cooking tasks: chopping vegetables, stirring a sauce, and watching an oven. They're not doing all three at the exact same instant, but they are managing them in an overlapping timeframe. Most asynchronous programming models achieve concurrency.
- Parallelism: Involves the actual, simultaneous execution of multiple tasks at the exact same instant. This requires multiple processing units (e.g., multiple CPU cores or separate machines). If a chef had two assistants, they could genuinely be chopping vegetables and stirring the sauce at the same time. When you have a multi-core processor and your asynchronous code is designed to use thread pools or worker processes, you can achieve true parallelism for CPU-bound tasks. However, for network I/O, the bottleneck is often the network itself and the remote server's response time, not your local CPU. Therefore, most asynchronous
apicalls primarily benefit from concurrency (allowing your local application to do other things while waiting) rather than strict parallelism (though some systems might use parallel threads to handle multiple incoming client requests, each of which then performs concurrent API calls).
For asynchronous API calls, the primary goal is often concurrency: ensuring that your application doesn't sit idle waiting for an API response but rather initiates multiple requests and then processes their responses as they arrive, freeing up its resources for other work in the interim.
Common Asynchronous Patterns
Over the years, various programming patterns have evolved to manage asynchronous operations, each with its strengths and weaknesses.
1. Callbacks
Callbacks were one of the earliest and most straightforward ways to handle asynchronous results. A callback is a function that is passed as an argument to another function, to be executed after the initial function has completed its task.
How it works: You make an api request and provide a callback function. When the api response arrives (or an error occurs), the callback function is invoked with the result or error.
Example (Conceptual JavaScript):
// Synchronous style (bad for APIs)
// const data = fetchDataSync("api.example.com/data");
// process(data);
// Asynchronous with callback
fetchDataAsync("api.example.com/data", function(error, data) {
if (error) {
console.error("Error fetching data:", error);
} else {
process(data);
}
});
console.log("Request initiated, continuing with other tasks...");
Pros: Simple for single asynchronous operations. Cons: * Callback Hell (Pyramid of Doom): When multiple asynchronous operations need to be chained sequentially, with each subsequent operation depending on the previous one's result, the code quickly becomes deeply nested and unreadable. * Error Handling: Propagating errors through nested callbacks can be challenging. * Inversion of Control: The calling code loses direct control over when the callback is executed.
2. Promises/Futures
Promises (in JavaScript) or Futures (in Java, Python) represent a value that might be available now, or in the future, or never. They provide a cleaner, more manageable way to handle asynchronous operations and chain them. A Promise can be in one of three states: * Pending: Initial state, neither fulfilled nor rejected. * Fulfilled (Resolved): The operation completed successfully, and the promise has a resulting value. * Rejected: The operation failed, and the promise has a reason for the failure.
How it works: An asynchronous function returns a Promise. You attach .then() handlers to process the successful result and .catch() handlers to deal with errors.
Example (Conceptual JavaScript with Promises):
// Function returns a Promise
function fetchDataPromise(url) {
return new Promise((resolve, reject) => {
// Simulate an async API call
setTimeout(() => {
const success = Math.random() > 0.1; // 90% success rate
if (success) {
resolve({ message: `Data from ${url}` });
} else {
reject(new Error(`Failed to fetch ${url}`));
}
}, 500);
});
}
// Chain promises
fetchDataPromise("api.example.com/data1")
.then(data1 => {
console.log("Received data1:", data1);
return fetchDataPromise("api.example.com/data2"); // Chain another promise
})
.then(data2 => {
console.log("Received data2:", data2);
// Both data1 and data2 are available here if sequential
// For parallel, use Promise.all (see below)
})
.catch(error => {
console.error("An error occurred:", error);
});
console.log("Promises initiated, continuing with other tasks...");
For parallel calls to two APIs, Promises excel with Promise.all():
Promise.all([
fetchDataPromise("api.example.com/data1"),
fetchDataPromise("api.example.com/data2")
])
.then(results => {
const [data1, data2] = results;
console.log("All data received concurrently:");
console.log("Data1:", data1);
console.log("Data2:", data2);
})
.catch(error => {
// If ANY of the promises in Promise.all() reject, the entire Promise.all() rejects
console.error("One of the API calls failed:", error);
});
Pros: * Readability: Flatter code structure compared to nested callbacks. * Chainability: Easy to chain multiple asynchronous operations sequentially. * Error Handling: Centralized error handling with .catch(). * Composition: Promise.all() (or Promise.race(), Promise.any(), Promise.allSettled()) allows for powerful composition of multiple promises, making parallel execution straightforward.
Cons: Can still involve .then() chaining, which might become long for very complex flows.
3. Async/Await
async/await is syntactic sugar built on top of Promises, designed to make asynchronous code look and behave more like synchronous code, significantly improving readability and maintainability. It's widely adopted in JavaScript, Python, C#, and other languages.
asynckeyword: Used to define a function that will perform asynchronous operations. Anasyncfunction implicitly returns a Promise.awaitkeyword: Can only be used inside anasyncfunction. It pauses the execution of theasyncfunction until the Promise it's "awaiting" resolves or rejects. Importantly, it does not block the entire program's execution; it only pauses theasyncfunction itself, allowing the event loop to handle other tasks.
Example (Conceptual JavaScript with Async/Await):
async function sendDataToTwoAPIs() {
try {
console.log("Initiating API calls...");
// This makes calls in parallel
const [response1, response2] = await Promise.all([
fetchDataPromise("api.example.com/data1"), // Assume fetchDataPromise returns a Promise
fetchDataPromise("api.example.com/data2")
]);
console.log("Received response from API 1:", response1);
console.log("Received response from API 2:", response2);
// Process both responses here
return { api1Result: response1, api2Result: response2 };
} catch (error) {
console.error("An error occurred during API calls:", error);
throw error; // Re-throw the error for external handling
}
}
// Call the async function
sendDataToTwoAPIs()
.then(results => console.log("All operations completed:", results))
.catch(error => console.error("Top-level error handler:", error));
console.log("Async function invoked, main thread continuing...");
Pros: * Readability: Code looks synchronous, making it much easier to reason about control flow. * Error Handling: Standard try...catch blocks can be used, just like synchronous code. * Debugging: Stepping through async/await code in a debugger is generally easier than with callbacks or raw Promise chains.
Cons: Requires careful use; forgetting await can lead to unexpected behavior (returning pending promises instead of their resolved values).
4. Event Loops
The event loop is a fundamental mechanism in single-threaded, non-blocking I/O environments like Node.js (JavaScript) and Python's asyncio. It enables concurrency without traditional multi-threading.
How it works: The event loop continuously monitors a queue of events (e.g., a timer expiring, an API response arriving, a user click). When an event occurs, the event loop takes the corresponding callback or task from the queue and executes it. If a task involves an I/O operation (like an API call), it initiates the operation and registers a callback. While waiting for the I/O to complete, the event loop does not block; instead, it picks up and executes other tasks from the queue. When the I/O operation finishes, its callback is added to the queue to be processed later.
Example (Conceptual Node.js):
// Node.js uses an event loop
const http = require('http');
http.createServer((req, res) => {
// This server can handle many concurrent requests
// because I/O operations (like database queries, API calls)
// are non-blocking and managed by the event loop.
if (req.url === '/api-data') {
// Simulate two async API calls
Promise.all([
fetchExternalAPI('url1'),
fetchExternalAPI('url2')
]).then(results => {
res.writeHead(200, { 'Content-Type': 'application/json' });
res.end(JSON.stringify(results));
}).catch(error => {
res.writeHead(500, { 'Content-Type': 'application/json' });
res.end(JSON.stringify({ error: error.message }));
});
} else {
res.writeHead(200);
res.end('Hello World');
}
}).listen(3000, () => {
console.log('Server running on port 3000');
});
// A dummy async function
function fetchExternalAPI(url) {
return new Promise(resolve => {
setTimeout(() => resolve(`Data from ${url}`), Math.random() * 1000 + 500);
});
}
Pros: Highly efficient for I/O-bound tasks, scales well with many concurrent connections, simple programming model (single thread logic). Cons: Can be challenging to debug if a long-running CPU-bound task accidentally blocks the event loop.
Language-Specific Implementations
The fundamental concepts translate into concrete implementations across various programming languages:
- Python:
asynciomodule,awaitandasynckeywords,aiohttporhttpxfor async HTTP requests,concurrent.futures.ThreadPoolExecutorfor running blocking code in separate threads. - JavaScript: Promises,
async/await,fetchAPI for browser,axiosor Node.js's built-inhttpmodule with Promises/async/await for backend.Promise.all()is crucial for parallel calls. - Java:
CompletableFuture(Java 8+),Spring WebFlux(reactive programming), Project Loom (virtual threads, JEP 444) for simpler asynchronous I/O. - C#:
Task<T>,async/awaitkeywords,HttpClientfor HTTP requests,Task.WhenAll()for parallel execution. - Go: Goroutines and channels, which provide a very lightweight and idiomatic way to handle concurrency.
By mastering these core concepts and their language-specific manifestations, developers are well-equipped to design and implement efficient asynchronous communication strategies for multiple APIs.
Strategies for Efficient Asynchronous Data Sending to Two APIs
Once the foundational concepts of asynchronous programming are understood, the next step is to apply specific strategies to efficiently send data to multiple APIs. The choice of strategy often depends on the nature of the APIs, their interdependencies, and the desired error handling characteristics.
1. Parallel Request Execution
The most straightforward and often most efficient strategy for sending data to two independent APIs is to initiate both requests simultaneously, allowing them to proceed concurrently. This approach drastically reduces the total execution time compared to sequential calls, as the application only waits for the slowest of the two responses.
Scenario: You need to update a user's profile in a CRM api and simultaneously log an event in an analytics api. Neither operation depends on the other's immediate response.
Implementation (Conceptual using async/await and Promises):
The key here is to use a construct that allows for multiple promises to be awaited together.
// Example: JavaScript with async/await
async function updateAcrossSystems(userData, analyticsEvent) {
try {
console.log("Initiating parallel API calls...");
// Create promises for both API calls
const crmUpdatePromise = sendDataToCRM(userData);
const analyticsLogPromise = sendDataToAnalytics(analyticsEvent);
// Await both promises simultaneously
// Promise.all waits for ALL promises to settle (resolve or reject)
const [crmResponse, analyticsResponse] = await Promise.all([
crmUpdatePromise,
analyticsLogPromise
]);
console.log("CRM Update Response:", crmResponse);
console.log("Analytics Log Response:", analyticsResponse);
// Further processing with both responses
return {
crmSuccess: true,
analyticsSuccess: true,
crmResult: crmResponse,
analyticsResult: analyticsResponse
};
} catch (error) {
console.error("One or more parallel API calls failed:", error);
// If Promise.all rejects, it's because at least one of the input promises rejected.
// The error object here will be the error from the *first* promise that rejected.
throw new Error(`Failed to update across systems: ${error.message}`);
}
}
// Dummy API functions returning Promises
async function sendDataToCRM(data) {
console.log("Sending data to CRM...");
// Simulate network delay and potential failure
return new Promise((resolve, reject) => {
setTimeout(() => {
if (Math.random() > 0.05) { // 95% success rate
resolve({ status: 'CRM_SUCCESS', id: 'crm-abc-123', data: data });
} else {
reject(new Error('CRM API Error: Could not update record.'));
}
}, Math.random() * 1000 + 500); // 500ms to 1.5s
});
}
async function sendDataToAnalytics(event) {
console.log("Sending data to Analytics...");
return new Promise((resolve, reject) => {
setTimeout(() => {
if (Math.random() > 0.05) { // 95% success rate
resolve({ status: 'ANALYTICS_SUCCESS', eventId: 'event-xyz-456', event: event });
} else {
reject(new Error('Analytics API Error: Failed to log event.'));
}
}, Math.random() * 800 + 300); // 300ms to 1.1s
});
}
// How to call it:
updateAcrossSystems({ name: "Alice", email: "alice@example.com" }, { type: "user_signup", source: "web" })
.then(results => console.log("Overall success:", results))
.catch(error => console.error("Overall failure:", error.message));
console.log("Application continues while API calls are in flight...");
Key Advantages: * Maximum Speed: The primary benefit is speed, as the total time is bounded by the slowest individual api call, not their sum. * Simplicity for Independent Calls: For APIs that don't depend on each other, this pattern is relatively simple to implement using language-provided concurrency primitives.
Considerations: * Error Handling: If any promise within Promise.all (or equivalent) rejects, the entire Promise.all immediately rejects with the error of the first promise that failed. If you need to know the status of all promises even if some fail, Promise.allSettled (or language equivalent) is more suitable, as it returns an array of objects describing the outcome of each promise (fulfilled or rejected). * Resource Usage: Initiating many parallel requests could potentially overwhelm the client machine's network stack or the target APIs if not managed carefully (e.g., hitting rate limits).
2. Sequential vs. Parallel (Conditional Execution)
Not all multi-API interactions are purely independent. Sometimes, one api call must complete successfully before another can even be initiated, typically because the second call requires data (like an ID or a token) from the first. However, even in such scenarios, we can maintain an asynchronous flow, ensuring the application itself doesn't block.
Scenario: A user signs up. First, you need to create the user record in your authentication api to get a userId. Then, using that userId, you create a corresponding profile in a separate user profile api.
Implementation (Conceptual using async/await for sequential dependency, but non-blocking):
async function registerUserAndProfile(username, password, profileData) {
try {
console.log("Initiating sequential API calls (Auth then Profile)...");
// Step 1: Create user in Authentication API
const authResponse = await createUserInAuthAPI(username, password);
const userId = authResponse.userId;
console.log(`User created in Auth API with ID: ${userId}`);
// Step 2: Use userId to create profile in Profile API
const profileResponse = await createProfileInProfileAPI(userId, profileData);
console.log("Profile created in Profile API:", profileResponse);
return {
userId: userId,
profileId: profileResponse.profileId,
status: "SUCCESS"
};
} catch (error) {
console.error("Error during user registration and profile creation:", error);
throw new Error(`Registration failed: ${error.message}`);
}
}
// Dummy API functions returning Promises
async function createUserInAuthAPI(username, password) {
console.log(`Creating user '${username}' in Auth API...`);
return new Promise((resolve, reject) => {
setTimeout(() => {
if (Math.random() > 0.1) {
resolve({ status: 'AUTH_SUCCESS', userId: `user-${Date.now()}` });
} else {
reject(new Error('Auth API: User creation failed.'));
}
}, Math.random() * 800 + 400); // 400ms to 1.2s
});
}
async function createProfileInProfileAPI(userId, profileData) {
console.log(`Creating profile for user '${userId}' in Profile API...`);
return new Promise((resolve, reject) => {
setTimeout(() => {
if (Math.random() > 0.1) {
resolve({ status: 'PROFILE_SUCCESS', profileId: `profile-${userId}` });
} else {
reject(new Error('Profile API: Profile creation failed.'));
}
}, Math.random() * 700 + 300); // 300ms to 1s
});
}
// How to call it:
registerUserAndProfile("johndoe", "secure_password", { fullName: "John Doe", country: "USA" })
.then(result => console.log("User registered successfully:", result))
.catch(error => console.error("Failed to register user:", error.message));
console.log("Application continues while Auth and Profile APIs are processing...");
Key Advantages: * Correctness for Dependencies: Ensures that dependent operations are executed in the correct order. * Readability: async/await makes sequential asynchronous logic as easy to read as synchronous code.
Considerations: * Cumulative Latency: While non-blocking, the total time for this operation is the sum of the individual API call times. Identify critical paths where dependencies exist and parallelize non-dependent tasks around them. * Error Handling: A failure in an earlier await statement will prevent subsequent await statements from executing, which is often the desired behavior for dependent operations. try...catch blocks handle this gracefully.
3. Batching Requests
For APIs that support it, batching multiple individual data submissions into a single request can significantly improve efficiency by reducing the number of network round trips. This is less about asynchronous initiation to two different APIs and more about optimizing interaction with a single API that might be involved in a larger multi-API workflow.
Scenario: You need to update 100 inventory items, and your inventory management api offers a /batch-update endpoint.
Implementation: Instead of 100 individual PUT requests, consolidate them into one POST request to the batch endpoint.
// Example: Conceptual batch update function
async function batchUpdateInventory(itemsToUpdate) {
try {
console.log(`Sending batch update for ${itemsToUpdate.length} items...`);
const response = await fetch('/api/inventory/batch-update', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(itemsToUpdate)
});
if (!response.ok) {
throw new Error(`Batch update failed: ${response.statusText}`);
}
const result = await response.json();
console.log("Batch update successful:", result);
return result;
} catch (error) {
console.error("Error during batch inventory update:", error);
throw error;
}
}
Key Advantages: * Reduced Network Overhead: Fewer HTTP headers, TCP handshakes, and round trips. * Improved Throughput: Servers can often process batches more efficiently than many individual requests. * Rate Limit Friendly: A single batch request often counts as one request against an api's rate limit.
Considerations: * API Support: Only applicable if the target API explicitly supports batch operations. * Failure Handling: If one item in a batch fails, how does the api report it? Does it roll back the entire batch or allow partial success? Your client code needs to handle these scenarios. * Payload Size: Batch requests can have large payloads. Ensure the api and network infrastructure can handle the size.
4. Robust Error Handling and Retries
Given the inherent unreliability of networks and external services, robust error handling and intelligent retry mechanisms are paramount for any efficient asynchronous multi-api interaction.
- Idempotent Operations: Design your data submission operations to be idempotent. This means that sending the same request multiple times has the same effect as sending it once. This is crucial for safe retries, preventing duplicate data creation or unintended side effects. For example, creating a user should involve a unique ID that the
apican use to detect if the user already exists.
Retry Logic with Exponential Backoff: For transient errors (e.g., network timeouts, HTTP 5xx errors from the api, or 429 Too Many Requests), simply retrying immediately might exacerbate the problem. Exponential backoff involves waiting for increasingly longer periods between retries. This gives the api or network time to recover.``javascript async function callAPIRetry(apiCallFn, maxRetries = 3, initialDelay = 1000) { let retries = 0; while (retries < maxRetries) { try { return await apiCallFn(); } catch (error) { console.warn(API call failed (attempt ${retries + 1}/${maxRetries}): ${error.message}`); if (retries === maxRetries - 1) throw error; // Re-throw if last attempt failed
const delay = initialDelay * Math.pow(2, retries) + Math.random() * 500; // Exponential + jitter
console.log(`Retrying in ${delay}ms...`);
await new Promise(resolve => setTimeout(resolve, delay));
retries++;
}
}
}// Usage: // await callAPIRetry(() => sendDataToCRM(userData)); `` * **Circuit Breaker Pattern:** This pattern helps prevent cascading failures when a service is failing. Instead of continuously trying to connect to a failingapi, the circuit breaker "trips" (opens) after a certain number of failures, quickly failing subsequent requests to thatapifor a predefined duration. After the duration, it enters a "half-open" state, allowing a few test requests to see if theapi` has recovered. If successful, it "closes" the circuit; otherwise, it opens again. This saves resources and prevents the calling application from becoming unresponsive due to waiting for a continuously failing dependency. Libraries like Polly for .NET, Hystrix (legacy) or Resilience4j for Java, and many custom implementations for Node.js/Python provide this functionality.
5. Timeouts
Crucial for asynchronous operations, timeouts prevent an application from waiting indefinitely for an unresponsive api. Every api call should have a defined timeout.
Implementation: Most HTTP client libraries offer timeout configurations.
// Example: Node.js fetch with AbortController for timeout
async function fetchWithTimeout(url, options = {}, timeout = 5000) { // Default 5 seconds
const controller = new AbortController();
const id = setTimeout(() => controller.abort(), timeout);
try {
const response = await fetch(url, {
...options,
signal: controller.signal
});
clearTimeout(id);
return response;
} catch (error) {
clearTimeout(id);
if (error.name === 'AbortError') {
throw new Error(`API call to ${url} timed out after ${timeout}ms.`);
}
throw error;
}
}
// Usage:
// await fetchWithTimeout('https://api.example.com/data', { method: 'POST', body: JSON.stringify(payload) }, 3000);
Key Considerations: * Appropriate Duration: Set timeouts realistically based on expected api response times and acceptable user waiting periods. Too short, and you might prematurely abort valid requests; too long, and you tie up resources. * Per-API vs. Global: It's often beneficial to configure specific timeouts for different APIs based on their known performance characteristics.
6. Load Balancing and Throttling (Client-side)
While server-side api gateways handle much of this, client-side mechanisms can complement them, especially when interacting with diverse third-party APIs with varying constraints.
- Client-side Throttling/Queueing: If you need to send many requests to an
apithat has strict rate limits, you can implement a local queue and a rate limiter. Requests are added to the queue and processed at a controlled rate (e.g., 5 requests per second), ensuring you don't exceed theapi's limit. This is particularly useful for background tasks or bulk data transfers. - Concurrency Limits: For parallel requests, you might want to limit the maximum number of concurrent requests to avoid overwhelming your own application's resources or saturating your network connection, especially when fetching data from many different sources simultaneously. Libraries exist to manage "worker pools" for this purpose.
These strategies, when combined thoughtfully, allow developers to build highly efficient and resilient systems that gracefully handle the complexities of asynchronous data submission to multiple APIs.
The Role of an API Gateway in Efficient Asynchronous Communication
While implementing asynchronous patterns at the application level provides significant benefits, the complexities of managing diverse api interactions, especially at scale, can quickly become overwhelming. This is where an api gateway emerges as a crucial architectural component, offering a centralized and robust solution to streamline and enhance asynchronous communication with multiple backend services. An api gateway acts as a single entry point for all client requests, abstracting the internal api landscape and offloading common concerns from individual microservices.
What is an API Gateway?
At its core, an api gateway is a server that acts as the single point of entry for a group of APIs. It's often described as a "reverse proxy" that accepts API calls, aggregates the necessary services, and routes them to the appropriate backend service. In a microservices architecture, clients interact with the api gateway, which then handles the routing of requests to specific microservices, potentially transforming requests and responses along the way.
Centralized Concerns Handled by an API Gateway:
An api gateway is designed to address a multitude of cross-cutting concerns that would otherwise need to be implemented (and maintained) in every single backend service or client application:
- Authentication and Authorization: Centralizing security ensures that all
apirequests are properly authenticated and authorized before reaching backend services, simplifying security management. - Rate Limiting and Throttling: The gateway can enforce granular rate limits for individual clients or APIs, preventing abuse and protecting backend services from overload.
- Request and Response Transformation: It can modify request parameters or body content before forwarding to backend services, or transform backend responses before sending them back to clients. This is invaluable when integrating with legacy systems or disparate
apiformats. - Logging and Monitoring: Centralized logging of all
apirequests and responses provides a unified view of system activity and performance, aiding in debugging and operational intelligence. - Caching: The gateway can cache responses from backend services, reducing the load on those services and improving response times for frequently accessed data.
- Load Balancing: Distributing incoming
apirequests across multiple instances of a backend service to optimize resource utilization and ensure high availability. - Service Discovery: Dynamically locating backend services, especially important in dynamic microservices environments.
- API Versioning: Managing different versions of an API, allowing clients to gradually migrate to newer versions without disrupting older integrations.
How an API Gateway Enhances Asynchronous Multi-API Communication
The true power of an api gateway in the context of asynchronous communication lies in its ability to orchestrate complex interactions with multiple backend APIs on behalf of the client. This offloading of complexity from the client yields significant benefits:
- Orchestration and Aggregation:
- Fan-out: A single client request to the
api gatewaycan trigger multiple concurrent calls to different backend services. For example, a client requestsGET /user-dashboard. The gateway might then asynchronously call theprofileservice, theordersservice, and thenotificationsservice in parallel. - Aggregation: After receiving responses from all internal services, the gateway can aggregate and transform these disparate responses into a single, unified response tailored for the client. This significantly simplifies client-side logic, as the client only needs to make one
apicall and receive one consolidated response, rather than managing multipleapicalls and their asynchronous responses.
- Fan-out: A single client request to the
- Client Logic Simplification: Without an
api gateway, a client application would need to:- Know the specific endpoints of two or more backend APIs.
- Implement its own asynchronous patterns (like
Promise.allorasyncio.gather). - Handle error conditions from each individual
api. - Combine data from multiple responses. The
api gatewayabstracts all this away. The client simply calls a single endpoint on the gateway, and the gateway handles the internal choreography of asynchronous calls, error management, and data aggregation. This allows client developers to focus on user experience rather than intricate backend integration details.
- Enhanced Resilience (Gateway-Level):
- Retries and Circuit Breakers: An
api gatewaycan implement sophisticated retry logic and circuit breaker patterns internally for calls to its backend services. If a backendapiis slow or failing, the gateway can handle retries with exponential backoff, or open a circuit to prevent cascading failures, without the client even being aware of the transient issue. This provides a crucial layer of fault tolerance. - Timeouts: The gateway can enforce different timeouts for its internal calls to various backend services, protecting the client from waiting indefinitely for a slow service.
- Retries and Circuit Breakers: An
- Reduced Network Round Trips: For a client, interacting with an
api gatewaymeans only one network round trip to send a request and one to receive a consolidated response, even if that request triggers multiple internal backendapicalls. This significantly reduces overall network latency for multi-API operations compared to a client making individual calls to multiple services. - Scalability and Maintainability for Microservices: In a microservices architecture, the
api gatewaybecomes essential. It allows independent development and deployment of backend services, as clients are decoupled from their specific locations and versions. Changes to a backendapi(e.g., its URL or internal structure) can be managed at the gateway level without impacting client applications. This enhances the scalability and maintainability of the entire system. - Protocol Transformation: The gateway can translate between different communication protocols. For instance, a client might send a standard HTTP/REST request to the gateway, which then translates and forwards it as a gRPC call or even a message to a queue (like Kafka) to a backend service. This flexibility supports diverse backend technologies while presenting a unified interface to clients.
For organizations grappling with the complexities of API management and asynchronous orchestration, an advanced api gateway solution can be transformative. Consider, for instance, APIPark, an open-source AI gateway and API management platform. APIPark excels in unifying various API services, including those powered by AI models, and provides robust features for end-to-end API lifecycle management. Its ability to manage traffic forwarding, load balancing, and even orchestrate calls to multiple backend services can significantly streamline the process of asynchronously sending data to two APIs or more. By centralizing common concerns like authentication, rate limiting, and request routing, APIPark allows developers to focus on core business logic rather than intricate asynchronous network interactions. Its capacity for quick integration of over 100 AI models and its unified API format for AI invocation further demonstrate its utility in scenarios where diverse and complex apis, including intelligent services, need to communicate efficiently. With performance rivaling Nginx and comprehensive logging capabilities, APIPark enhances not only the efficiency of asynchronous data sending but also bolsters security, scalability, and maintainability across diverse api landscapes. Its independent API and access permissions for each tenant, alongside its API resource access approval features, ensure a secure and controlled environment for multi-api operations.
In essence, while asynchronous programming is about how your application manages its waiting time for API responses, an api gateway is about offloading the intricate coordination of multiple API responses, insulating clients from complexity, and providing a centralized point for managing critical cross-cutting concerns that are vital for efficient and resilient multi-api communication.
APIPark is a high-performance AI gateway that allows you to securely access the most comprehensive LLM APIs globally on the APIPark platform, including OpenAI, Anthropic, Mistral, Llama2, Google Gemini, and more.Try APIPark now! 👇👇👇
Practical Implementation Considerations
Moving from theoretical understanding to practical implementation of efficient asynchronous multi-api communication requires attention to several critical aspects that ensure the robustness, observability, and security of your system.
Monitoring and Logging: The Eyes and Ears of Your System
When dealing with asynchronous operations across multiple APIs, traditional debugging techniques can fall short. The non-linear flow of execution means that understanding "what happened when" is paramount. Robust monitoring and logging are not just good practices; they are indispensable.
- Detailed Request/Response Logging: Log every
apirequest made from your application, including the targetapi, endpoint, payload (sanitized to remove sensitive data), and timestamps. Critically, log the corresponding response, including HTTP status codes, response bodies (again, sanitized), and the time taken for theapicall. This provides a clear audit trail. - Correlation IDs: Implement correlation IDs (also known as request IDs or trace IDs) that are passed through your entire system, from the initial client request to all subsequent internal and external
apicalls. When a client initiates an operation that triggers calls to two externalapis, ensure a consistent correlation ID is used for all these related logs. This allows you to trace a single user interaction across distributed services, making it significantly easier to diagnose issues like delays, failures, or inconsistencies across multipleapiresponses. - Performance Metrics: Monitor key metrics for each
apicall:- Latency: Time from request initiation to response reception. Track average, p95, p99 latency to identify performance bottlenecks.
- Throughput: Number of requests per second/minute.
- Error Rates: Percentage of failed
apicalls (e.g., 4xx, 5xx responses). - Timeouts: Count of requests that hit a timeout. These metrics, ideally visualized in a dashboard (e.g., Prometheus, Grafana, Datadog), provide real-time insights into the health and performance of your
apiintegrations.
- Distributed Tracing: For complex microservices environments, adopt distributed tracing tools (e.g., OpenTelemetry, Jaeger, Zipkin). These tools automatically propagate trace contexts (including correlation IDs) across service boundaries, allowing you to visualize the entire request flow and pinpoint which specific
apicall or internal service contributed to latency or errors. Anapi gatewaylike APIPark, with its detailed API call logging and powerful data analysis features, can be a central hub for collecting and visualizing this critical operational intelligence, making it easier to identify long-term trends and performance changes before they become critical issues.
Testing: Ensuring Reliability and Correctness
Thorough testing is crucial to ensure that your asynchronous multi-api logic behaves correctly under various conditions, especially given the non-deterministic nature of network communication.
- Unit Tests: Test your individual functions that make
apicalls in isolation. Mock the actualapicalls to control their responses (success, different error codes, various latencies) and verify that your functions handle these scenarios correctly, including retries, error parsing, and data transformation. - Integration Tests: Test the complete flow of sending data to two APIs. Use test doubles (mocks or stubs) for the external APIs if they are expensive, slow, or unreliable in a test environment. These tests should verify that the data is correctly prepared, sent, and processed by both APIs, and that the application handles combined results or failures gracefully.
- End-to-End (E2E) Tests: Whenever possible, run E2E tests against actual (or very close to actual)
apis. This is particularly important for critical paths to ensure that the entire system, including networking and externalapiconfigurations, works as expected. Be mindful of rate limits and costs when running these tests. - Chaos Engineering: For highly critical systems, consider introducing controlled failures (e.g., making an
apiunresponsive, injecting network latency) to observe how your asynchronous error handling, retries, and circuit breakers behave in a real-world failure scenario.
Security: Protecting Data in Motion and at Rest
When sending sensitive data to multiple external APIs, security must be a top priority.
- Authentication and Authorization:
- API Keys/Tokens: Use strong, unique
apikeys or OAuth 2.0 tokens for authenticating with each externalapi. Ensure these credentials are never hardcoded and are securely managed (e.g., environment variables, secret management services). - Least Privilege: Configure
apicredentials with the minimum necessary permissions for the tasks they perform. - An
api gatewaycentralizes these concerns. It can authenticate incoming client requests, and then itself use different, more privileged credentials when interacting with backend services, thereby acting as a security proxy. APIPark, for example, allows for independent API and access permissions for each tenant and supports subscription approval features, ensuring that only authorized callers can invoke APIs after administrator approval.
- API Keys/Tokens: Use strong, unique
- Data Encryption (TLS/SSL): Always use HTTPS for all
apicommunications. This encrypts data in transit, protecting it from eavesdropping and tampering. Most modernapis enforce HTTPS by default. - Data Sanitization and Validation: Before sending any data to an external
api, always sanitize and validate it on your application's side. This prevents injection attacks and ensures that you're sending well-formed data, reducing the likelihood ofapierrors. - Sensitive Data Handling:
- Minimize Data Transmission: Only send the absolute minimum data required by each
api. - Data Masking/Tokenization: For highly sensitive information (e.g., credit card numbers, PII), consider masking, tokenizing, or encrypting data before sending it to third-party
apis. - Never Log Sensitive Data: Ensure your logging system is configured to strip or mask any sensitive data before it's written to logs.
- Minimize Data Transmission: Only send the absolute minimum data required by each
Scalability: Designing for Growth
Asynchronous communication inherently improves scalability by making efficient use of resources. However, explicit design choices are still needed to ensure your application can handle increased load.
- Horizontal Scaling: Design your application to be stateless, allowing you to run multiple instances behind a load balancer. If one instance makes an
apicall, its state should not be dependent on that specific instance, enabling any instance to handle subsequent steps or requests. - Resource Management (Connection Pools): HTTP client libraries often manage connection pools. Ensure these are configured appropriately. Reusing existing TCP connections reduces overhead and latency for subsequent
apicalls to the same host. Avoid creating a new HTTP client for every request. - Bounded Concurrency: While parallelizing
apicalls is good, unlimited concurrency can exhaust local resources (CPU, memory, network sockets) or overwhelm the targetapis (leading to rate limit issues). Implement a mechanism to limit the number of concurrent outstanding requests if you're making many calls. This creates backpressure and prevents your system from collapsing under extreme load. - Load Testing: Before deploying to production, subject your application to load tests to simulate high traffic and multiple concurrent
apicalls. This helps identify bottlenecks, resource leaks, and potential scaling issues under realistic conditions.
By meticulously addressing these practical considerations, developers can build asynchronous multi-api integration solutions that are not only efficient but also reliable, secure, and ready for future growth.
Case Studies and Scenarios: Real-World Applications
To solidify the understanding of asynchronously sending data to two APIs efficiently, let's explore a few real-world scenarios where these techniques are applied, highlighting the benefits and complexities involved.
1. E-commerce Checkout: Orchestrating Post-Payment Actions
Consider a typical e-commerce checkout process. After a user successfully submits their payment, several critical backend operations need to occur. Performing these synchronously would significantly delay the confirmation message to the user, leading to a poor experience.
Scenario: A user completes a purchase. The application needs to: 1. Update Inventory (Inventory API): Decrement stock levels for the purchased items. 2. Process Payment (Payment Gateway API): This is typically done before the post-payment flow, but its success triggers the next set of actions. 3. Create Order Record (Order Management API): Persist the new order details. 4. Send Confirmation Email (Notification API): Notify the user of their successful purchase. 5. Log for Analytics (Analytics API): Record the purchase event for business intelligence.
Asynchronous Strategy: The key operations post-payment (inventory update, order creation, email, analytics) are largely independent. The payment processing itself is often blocking by necessity (awaiting a successful transaction), but once confirmed, everything else can run concurrently.
async function handleSuccessfulPayment(paymentDetails, orderItems, customerInfo) {
try {
console.log("Payment confirmed. Initiating post-payment actions...");
// 1. Create Order (might be sequential if other ops need orderId)
// Let's assume Order API provides an orderId crucial for other operations.
const orderCreationPromise = createOrder(orderItems, customerInfo, paymentDetails.transactionId);
const orderResponse = await orderCreationPromise;
const orderId = orderResponse.orderId;
console.log(`Order ${orderId} created.`);
// 2. Perform other independent actions in parallel using the orderId
const [inventoryUpdateResult, emailSendResult, analyticsLogResult] = await Promise.all([
updateInventory(orderItems), // Independent of email/analytics, needs orderItems
sendOrderConfirmationEmail(customerInfo, orderId), // Needs orderId for email content
logPurchaseEvent(customerInfo, orderId, orderItems) // Needs orderId and item details
]);
console.log("Inventory Update Result:", inventoryUpdateResult);
console.log("Email Send Result:", emailSendResult);
console.log("Analytics Log Result:", analyticsLogResult);
// All post-payment actions initiated/completed. User can now be notified.
return { success: true, orderId: orderId, message: "Purchase successful!" };
} catch (error) {
console.error("Error during post-payment processing:", error);
// Implement compensating actions if necessary (e.g., refund, manual review)
throw new Error("Purchase initiated but some post-payment actions failed. Please check order status.");
}
}
// Dummy functions representing API calls
async function createOrder(items, customer, transactionId) { /* ... */ return { orderId: "ORD-12345" }; }
async function updateInventory(items) { /* ... */ return { status: "Inventory updated" }; }
async function sendOrderConfirmationEmail(customer, orderId) { /* ... */ return { status: "Email sent" }; }
async function logPurchaseEvent(customer, orderId, items) { /* ... */ return { status: "Event logged" }; }
Benefits: The user receives immediate confirmation, improving satisfaction. Backend operations are completed quickly, reducing load times. If one api (e.g., analytics) is slow or fails, it doesn't block critical operations like inventory update or order confirmation.
Complexity: Requires careful error handling for partial failures. If inventory update fails, a compensating action (e.g., notifying customer support, manual refund) might be needed. This is where eventual consistency patterns or message queues become relevant for critical, interdependent operations.
2. User Registration: Provisioning Across Multiple Services
When a new user signs up for a service, their data often needs to be provisioned across various internal systems or third-party integrations.
Scenario: A new user registers for a platform. The application needs to: 1. Create User Account (User Management API): Store core user credentials and generate a userId. 2. Subscribe to Newsletter (Marketing API): Add the user's email to the newsletter list. 3. Provision User Profile (Profile API): Create a detailed user profile linked to the userId. 4. Send Welcome Email (Email Service API): Greet the new user.
Asynchronous Strategy: The User Management API call is typically sequential, as it generates the userId needed by other services. The subsequent calls can then run in parallel.
async function registerNewUser(username, password, email, profileDetails) {
try {
console.log("Starting new user registration...");
// Step 1: Create the core user account (sequential dependency for userId)
const userAccountResponse = await createUserAccount(username, password, email);
const userId = userAccountResponse.userId;
console.log(`Core user account created with ID: ${userId}`);
// Step 2: Trigger parallel provisioning and notification tasks
const [newsletterResult, profileProvisionResult, welcomeEmailResult] = await Promise.all([
subscribeToNewsletter(email),
provisionUserProfile(userId, profileDetails),
sendWelcomeEmail(email, username)
]);
console.log("Newsletter Subscription:", newsletterResult);
console.log("Profile Provisioning:", profileProvisionResult);
console.log("Welcome Email:", welcomeEmailResult);
return { success: true, userId: userId, message: "User registered and provisioned successfully." };
} catch (error) {
console.error("User registration failed:", error);
// Implement rollbacks or compensation for partial failures.
// E.g., if profile provisioning failed, mark user as incomplete or notify admin.
throw new Error(`Failed to register user: ${error.message}`);
}
}
// Dummy functions
async function createUserAccount(username, password, email) { /* ... */ return { userId: `USR-${Date.now()}` }; }
async function subscribeToNewsletter(email) { /* ... */ return { status: "Subscribed" }; }
async function provisionUserProfile(userId, details) { /* ... */ return { status: "Profile created" }; }
async function sendWelcomeEmail(email, name) { /* ... */ return { status: "Email sent" }; }
Benefits: Fast user onboarding experience. The user sees "Registration Complete!" quickly, even if some background tasks like sending a welcome email are still in flight.
Complexity: If provisionUserProfile fails, the user might have an account but no profile. This requires careful design of consistency checks or event-driven systems to ensure eventual consistency. The api gateway can centralize a lot of this orchestration, providing a single endpoint for "registerUser" that internally fans out requests and handles partial failures with configured retries.
3. Data Aggregation and Transformation from External Sources
Many applications need to gather data from various third-party apis, combine it, and perhaps transform it before presenting it to the user or storing it internally.
Scenario: A travel planning application needs to fetch flight prices (Flight API) and hotel availability (Hotel API) for a given destination and dates to present a combined travel package.
Asynchronous Strategy: Both Flight API and Hotel API calls are independent and can be made in parallel. The results are then aggregated and processed.
async function fetchTravelPackage(destination, dates) {
try {
console.log(`Fetching travel details for ${destination} on ${dates.start} to ${dates.end}...`);
// Initiate both API calls in parallel
const [flightResponse, hotelResponse] = await Promise.all([
fetchFlights(destination, dates.start, dates.end),
fetchHotels(destination, dates.start, dates.end)
]);
console.log("Flight Data Received:", flightResponse.length, "flights");
console.log("Hotel Data Received:", hotelResponse.length, "hotels");
// Aggregate and transform the data
const combinedPackage = {
destination: destination,
dates: dates,
flights: flightResponse.flights.map(f => ({ id: f.id, price: f.price, airline: f.airline })),
hotels: hotelResponse.hotels.map(h => ({ name: h.name, pricePerNight: h.price, rating: h.rating })),
// Add more logic to find best combinations, etc.
};
console.log("Combined Travel Package Ready.");
return combinedPackage;
} catch (error) {
console.error("Failed to fetch travel package data:", error);
// Decide whether to return partial data or throw an error based on business rules
throw new Error(`Could not retrieve full travel package: ${error.message}`);
}
}
// Dummy functions
async function fetchFlights(dest, start, end) { /* ... */ return { flights: [{ id: "F1", price: 300, airline: "AirX" }] }; }
async function fetchHotels(dest, start, end) { /* ... */ return { hotels: [{ name: "Grand Hotel", price: 150, rating: 4.5 }] }; }
Benefits: Rapid display of comprehensive travel options to the user. The overall waiting time is dictated by the slowest of the flight or hotel API, not their sum.
Complexity: If one api fails (e.g., Flight API), do you show hotels only, or an error? Promise.allSettled can help here to gather all results regardless of individual success/failure and then apply business logic to handle partial data.
These case studies illustrate how asynchronous strategies, especially parallel execution with robust error handling, are indispensable for building responsive and efficient applications that interact with multiple APIs. They also underscore how an api gateway can abstract away much of this complexity, offering a more streamlined approach to service orchestration.
Performance Benchmarking and Optimization
Achieving efficiency in asynchronous multi-api communication is not just about writing non-blocking code; it's also about measuring its performance and continuously optimizing it. Without proper benchmarking, it's difficult to confirm if the chosen strategies are truly delivering the desired speed and resource utilization.
Measuring Latency and Throughput
The two most critical metrics for api performance are latency and throughput.
- Latency: The time taken for a single operation to complete. For an asynchronous call to two APIs, this typically means the duration from initiating the parallel requests to receiving both responses and completing any aggregation.
- Average Latency: Useful for general understanding.
- Percentiles (P95, P99): Crucial for identifying outliers and worst-case scenarios. A high P99 latency indicates that a small percentage of users are experiencing significant delays, even if the average is good.
- Throughput (Requests Per Second/Minute): The number of operations or transactions that a system can handle within a given timeframe. For multi-
apicalls, this might mean how many combined operations (e.g., user registrations, e-commerce checkouts) your system can process per second.
Benchmarking Tools and Techniques: * Load Testing Tools: Tools like JMeter, Locust, k6, Artillery, or ApacheBench can simulate a large number of concurrent users or requests, allowing you to measure throughput and latency under load. * Profiling Tools: Language-specific profilers (e.g., cProfile for Python, Node.js Inspector, Java Mission Control) can identify CPU-bound bottlenecks within your application that might be slowing down asynchronous task scheduling or data processing. * Synthetic Monitoring: Regularly making real or simulated api calls to your system (and through to the external APIs) from different geographical locations can provide ongoing performance insights and alert you to degradations. * Logging with Timestamps: As discussed, detailed logging with precise timestamps around api calls and processing steps is fundamental for calculating actual latencies in production.
A comprehensive api gateway solution like APIPark provides powerful data analysis features, allowing businesses to analyze historical call data to display long-term trends and performance changes. This capability is invaluable for identifying performance regressions and making data-driven optimization decisions.
Identifying Bottlenecks
Performance issues often stem from specific bottlenecks. For asynchronous multi-api operations, common bottlenecks include:
- Slowest External API: When using parallel execution (e.g.,
Promise.all), the overall latency is dictated by the slowestapiin the set. If oneapiconsistently takes significantly longer than others, it becomes the primary bottleneck for the combined operation. - Network Latency to External APIs: The geographical distance between your application and the external
apiservers, or general internet congestion, can introduce unavoidable delays. Using anapi gatewaydeployed closer to the external APIs or implementing caching can mitigate this. - Rate Limits: Hitting
apirate limits can cause requests to be delayed (if client-side throttling is in place) or rejected, severely impacting throughput. - Local Processing Overhead: While
apicalls are I/O-bound, the processing of requests and responses (e.g., JSON parsing, data transformation, database lookups before/afterapicalls) can become CPU-bound, especially under high load. If these tasks are blocking the event loop or consuming excessive CPU, they will negate the benefits of asynchronous I/O. - Database I/O: If your application performs database operations before or after the
apicalls, and these are synchronous or inefficient, they can become a bottleneck. Asynchronous database drivers are available in many languages (e.g.,asyncpgfor Python, R2DBC for Java). - Unoptimized Code: Inefficient loops, large data structures, or unnecessary computations can introduce delays.
Resource Utilization
Monitoring resource utilization (CPU, memory, network I/O) helps understand if your application is being starved or if you're over-provisioning. * CPU Usage: High CPU usage during asynchronous I/O might indicate that your application is doing too much CPU-bound work on the main event loop, or that there's a problem with garbage collection or thread contention. * Memory Usage: Memory leaks or excessive memory consumption can lead to slow performance and instability. * Network I/O: Observe outgoing and incoming network traffic to ensure it aligns with expectations. Excessive retransmissions or dropped packets can indicate network issues.
Choosing the Right API Client Library
The choice of HTTP client library can have a subtle but significant impact on performance, particularly regarding connection management and efficiency.
- Connection Pooling: A good HTTP client library will manage a pool of persistent TCP connections to target
apis. Reusing connections avoids the overhead of new TCP handshakes and TLS negotiations for every request, drastically improving performance. - Asynchronous Support: Ensure the client library is designed for asynchronous operations, natively returning Promises/Futures or integrating well with
async/await. - Performance and Features: Consider libraries known for performance, robust error handling, and features like retries, timeouts, and interceptors (for adding common headers, logging, etc.).
- Python:
httpx(modern, async-first),aiohttp(for event loop based applications).requestsis popular but primarily synchronous; it can be run in threads but is not truly async-native. - JavaScript (Node.js):
axios,node-fetch(closer to browserfetch), nativehttpmodule with Promises. - Java:
HttpClient(Java 11+),WebClient(Spring WebFlux),OkHttp. - C#:
HttpClient.
- Python:
Optimization Strategies
Once bottlenecks are identified, consider these optimization strategies:
- Reduce External API Calls:
- Caching: Implement caching for responses from external APIs, especially for data that doesn't change frequently. An
api gatewayoften provides robust caching capabilities. - Batching: As discussed, if an
apisupports it, batch multiple operations into a single request. - Webhooks: If feasible, subscribe to webhooks from external services instead of polling them, reducing unnecessary requests and providing real-time updates.
- Caching: Implement caching for responses from external APIs, especially for data that doesn't change frequently. An
- Optimize Network Interaction:
- HTTP/2 or HTTP/3: Use newer HTTP protocols if supported by both your client and the
api, as they offer benefits like multiplexing and header compression. - Content Compression: Ensure your
apirequests and responses use GZIP or Brotli compression to reduce data transfer size.
- HTTP/2 or HTTP/3: Use newer HTTP protocols if supported by both your client and the
- Optimize Local Processing:
- Efficient Data Structures and Algorithms: Review your code for any CPU-bound operations that can be optimized.
- Non-blocking I/O for Internal Services: If your application interacts with internal databases or message queues, ensure those interactions are also non-blocking.
- Offload CPU-bound Work: If you have CPU-intensive tasks that must run, consider offloading them to worker threads or separate processes to avoid blocking the main event loop responsible for I/O.
- Tune Asynchronous Parameters:
- Connection Pool Sizes: Adjust HTTP client connection pool sizes.
- Concurrency Limits: Fine-tune the number of concurrent
apirequests your application makes. - Retry Delays and Max Retries: Balance responsiveness with resilience.
- Consider an API Gateway: As highlighted, an
api gatewaycan offload significant complexity, centralize optimizations (caching, rate limiting, load balancing), and improve overall efficiency and resilience for multi-apiscenarios. APIPark, with its Nginx-rivaling performance and cluster deployment support, is designed precisely for handling large-scale traffic and optimizing these interactions.
By rigorously applying benchmarking, bottleneck analysis, and targeted optimization techniques, developers can ensure that their asynchronous multi-api communication strategies are not only correct but also perform exceptionally well under varying loads and conditions.
Advanced Topics in Asynchronous Data Sending
While parallel api calls with async/await and an api gateway cover a vast majority of use cases for efficiently sending data to two APIs, there are more advanced patterns and tools that can be employed for even greater resilience, scalability, and decoupling in highly distributed systems.
1. Webhooks for Real-Time Updates and Reactive Architectures
Instead of actively polling an API for updates (which can be inefficient and introduce latency), webhooks offer a push-based mechanism for real-time notifications.
How it works: Instead of your application continuously asking an external API, "Is there new data?", your application registers a URL (its "webhook endpoint") with the external API. When a specific event occurs on the external API's side (e.g., a payment is processed, an order status changes), the external API makes an HTTP POST request to your registered webhook endpoint, notifying your application in real-time.
Relevance to Multi-API Data Sending: While primarily a receiving mechanism, webhooks can significantly influence how you send data by enabling reactive architectures. * Decoupling: Instead of sending data to a second API immediately after the first, you might send data to API_A, and then API_A (or its associated system) fires a webhook when its processing is complete. Your application (or another service) then picks up this webhook and asynchronously sends data to API_B. This adds a layer of decoupling. * Reduced Polling: If API_B relies on the state created by API_A rather than just the immediate response, webhooks can eliminate the need for your application to poll API_A to check if its operation has finished. * Event-Driven Flows: Webhooks are a cornerstone of event-driven architectures, where services react to events rather than tightly coupled direct calls.
Considerations: * Security: Webhook endpoints must be highly secure (HTTPS, signature verification, IP whitelisting) to prevent malicious requests. * Reliability: You need a robust system to handle incoming webhooks, potentially queuing them for processing, and managing retries if your endpoint is temporarily unavailable. * External API Support: Only applicable if the external api offers webhook functionality.
2. Message Queues for Truly Decoupled Asynchronous Processing
For mission-critical operations, situations requiring guaranteed delivery, or extremely high volumes of data, message queues (or message brokers) provide an even higher degree of decoupling and resilience than direct asynchronous API calls. Popular message queues include RabbitMQ, Apache Kafka, Amazon SQS, Azure Service Bus, and Google Cloud Pub/Sub.
How it works: 1. Producer: Your application (the "producer") sends a message (containing data to be processed) to a message queue. This operation is typically very fast and non-blocking. 2. Queue: The message queue reliably stores the message. 3. Consumer: A separate, independent application (the "consumer" or "worker") continuously monitors the queue, retrieves messages, and performs the actual work (e.g., sending data to API_A, then to API_B).
Relevance to Multi-API Data Sending: * Asynchronous by Nature: Sending a message to a queue is inherently asynchronous and non-blocking. Your application can quickly enqueue tasks and immediately return to the user, providing an extremely fast response. * Guaranteed Delivery: Message queues are designed for persistence and often offer "at-least-once" or "exactly-once" delivery guarantees, ensuring that tasks are eventually processed even if consumers fail. * Resilience and Retry: If API_A or API_B is temporarily down, the consumer can simply put the message back into the queue or send it to a "dead-letter queue" for later processing, without impacting the original application. * Scalability: You can easily scale consumers horizontally to handle increased message volumes. * Load Spreading/Spikes: Queues buffer messages, helping to smooth out spikes in demand and preventing backend APIs from being overwhelmed. * Complex Workflows: For complex workflows involving multiple steps and APIs, messages can be passed between different queues and consumers, each handling a specific part of the process.
Scenario: User signs up, and multiple background tasks (email welcome, CRM sync, analytics logging) need to happen.
Application (Producer) -> Enqueue "UserSignedUp" message -> Message Queue
|
V
Worker 1 (Consumer) -> Calls Email API
|
V
Worker 2 (Consumer) -> Calls CRM API
|
V
Worker 3 (Consumer) -> Calls Analytics API
Considerations: * Increased Complexity: Introduces new infrastructure (the message queue) and the need to manage producers and consumers. * Operational Overhead: Message queues require monitoring and maintenance. * Eventual Consistency: Data processed through queues leads to eventual consistency. The system might not be immediately consistent across all services.
3. Serverless Functions for Event-Driven Asynchronous Processing
Serverless computing (e.g., AWS Lambda, Azure Functions, Google Cloud Functions) provides an elegant way to execute code in response to events, without provisioning or managing servers. This is highly synergistic with asynchronous and event-driven architectures.
How it works: You deploy small, single-purpose functions that are triggered by events (e.g., an HTTP request, a new message in a queue, a file upload). The cloud provider automatically scales and manages the underlying infrastructure.
Relevance to Multi-API Data Sending: * Event-Driven API Interactions: Your main application can quickly write data to a database or send a message to a queue. This event then triggers a serverless function. That function can then asynchronously send data to API_A and API_B in parallel. * Reduced Operational Burden: No servers to manage. Scaling is handled automatically. * Cost-Effective: You only pay for the compute time your functions consume. * Isolation: Each function is an isolated execution environment, making it easier to manage dependencies and failures.
Scenario: A file is uploaded to an S3 bucket. A serverless function is triggered to process the file and then upload metadata to API_A and a processed version to API_B.
User -> Uploads File -> S3 Bucket
|
V
S3 Event -> AWS Lambda Function (Serverless)
|
|-- Asynchronously calls API_A (metadata upload)
|-- Asynchronously calls API_B (processed file upload)
Considerations: * Cold Starts: Functions might experience a "cold start" delay if they haven't been invoked recently. * Vendor Lock-in: Code written for one serverless platform might not be easily portable to another. * Debugging and Observability: Can be challenging across distributed serverless functions.
By considering these advanced topics, developers can extend their asynchronous data sending capabilities beyond basic parallel api calls, building highly resilient, scalable, and decoupled systems fit for the most demanding enterprise environments. The decision to adopt these more complex patterns should always be driven by specific business requirements for reliability, throughput, and operational characteristics.
Conclusion
In the demanding landscape of modern software development, where applications are increasingly interconnected and user expectations for responsiveness are at an all-time high, the ability to efficiently send data to multiple APIs asynchronously is not merely an optimization; it is a fundamental pillar of robust system design. We've traversed the journey from understanding the core distinctions between synchronous and asynchronous operations, recognizing the critical challenges posed by network variability, rate limits, and error handling, to exploring concrete strategies like parallel execution, intelligent retries, and strategic timeouts.
The power of asynchronous programming, exemplified by patterns such as Promises and async/await, liberates applications from the blocking nature of I/O operations. By allowing multiple API calls to be in-flight concurrently, these techniques drastically reduce cumulative latency, enhance application throughput, and improve overall resource utilization. Whether it’s an e-commerce platform orchestrating post-payment actions or a user registration system provisioning accounts across various services, the shift to non-blocking api interactions ensures a smoother, faster, and more satisfying experience for the end-user.
However, as systems grow in complexity, particularly within microservices architectures, the task of manually orchestrating these multi-api interactions at the client level can become unwieldy. This is precisely where the strategic adoption of an api gateway becomes transformative. An api gateway acts as a powerful central nervous system, abstracting the complexities of multiple backend services, centralizing cross-cutting concerns like authentication, rate limiting, and logging, and crucially, streamlining the asynchronous orchestration and aggregation of data from disparate APIs. Solutions like APIPark, an open-source AI gateway and API management platform, exemplify how a robust api gateway can elevate system efficiency, resilience, and maintainability by providing a unified interface for diverse services, including advanced AI models, while offering granular control over the API lifecycle. Its ability to handle traffic forwarding, load balancing, and performance monitoring means developers can focus on innovation rather than infrastructure.
Ultimately, mastering the art of asynchronous data sending to two or more APIs requires a holistic approach: * Foundational Knowledge: A deep understanding of asynchronous patterns. * Strategic Implementation: Choosing the right parallel, sequential, or batching strategies. * Robust Handling: Meticulous error handling, retries, and timeouts. * Observability: Comprehensive monitoring, logging, and tracing. * Security & Scalability: Designing for inherent security and future growth. * Architectural Leverage: Judicious use of an api gateway to offload complexity and enhance system-wide capabilities.
By embracing these principles and tools, developers can build highly performant, resilient, and scalable applications that gracefully navigate the intricate world of multi-api communication, delivering superior user experiences in an ever-connected digital landscape. The journey to efficient asynchronous operations is continuous, driven by ongoing measurement, optimization, and the adoption of cutting-edge architectural patterns.
Frequently Asked Questions (FAQ)
1. What is the primary benefit of sending data asynchronously to two APIs compared to synchronously?
The primary benefit is a significant reduction in total execution time and improved application responsiveness. Synchronous calls block your application while waiting for each API response sequentially, leading to cumulative delays. Asynchronous calls allow your application to initiate both API requests concurrently and continue processing other tasks, effectively waiting only for the slowest of the two API responses rather than their sum.
2. When should I use Promise.all() (or equivalent) for sending data to multiple APIs?
You should use Promise.all() (or its language-specific equivalents like C#'s Task.WhenAll() or Python's asyncio.gather()) when you need to send data to two or more APIs that are independent of each other, and you require all operations to complete successfully before proceeding. It's ideal for parallel execution where the order of completion doesn't matter, but you need to consolidate all results.
3. What happens if one of the two asynchronous API calls fails when using Promise.all()?
If any of the promises passed to Promise.all() reject (i.e., one of the API calls fails), then the entire Promise.all() operation will immediately reject with the error of the first promise that failed. The results of other, potentially successful, promises will not be returned by Promise.all() in this scenario. If you need to know the outcome of all API calls, regardless of individual failures, you would typically use Promise.allSettled() (in JavaScript) or similar constructs.
4. How does an API Gateway help in asynchronously sending data to multiple APIs?
An api gateway acts as a central proxy that can receive a single client request and then internally orchestrate multiple asynchronous calls to different backend APIs on behalf of the client. It handles fan-out (sending requests to multiple APIs in parallel), aggregation (combining responses from those APIs), and cross-cutting concerns like authentication, rate limiting, and error handling. This offloads complexity from the client, simplifies client-side logic, improves resilience through centralized retries and circuit breakers, and reduces network round trips from the client.
5. What are idempotent operations, and why are they important for asynchronous API calls with retries?
An operation is idempotent if executing it multiple times has the same effect as executing it once. For example, setting a value to "active" is idempotent, but incrementing a counter is not. Idempotent operations are crucial for asynchronous API calls with retries because network unreliability can cause requests to be sent multiple times (due to retries) or cause an API to process a request but fail to send a response. If your data sending operations are idempotent, you can safely retry failed API calls without fear of creating duplicate data or causing unintended side effects, significantly improving the resilience of your asynchronous communication.
🚀You can securely and efficiently call the OpenAI API on APIPark in just two steps:
Step 1: Deploy the APIPark AI gateway in 5 minutes.
APIPark is developed based on Golang, offering strong product performance and low development and maintenance costs. You can deploy APIPark with a single command line.
curl -sSO https://download.apipark.com/install/quick-start.sh; bash quick-start.sh

In my experience, you can see the successful deployment interface within 5 to 10 minutes. Then, you can log in to APIPark using your account.

Step 2: Call the OpenAI API.

